Unicode
Unicode 是一个字符集,它把目前世界上所有字符包含在内了。每个符号都与一个称为代码点(Code Point)的十六进制数对应,代码点通常有一个U+前缀,例如:
1 | U+0041 => A |
Code Point 的取值范围是U+0000~U+10FFFF,大约有 110 万个。 为了好组织,所有Code Point被分为了 17 个Plane,每个Plane中大约包含 65K 个Code Point。 见维基百科
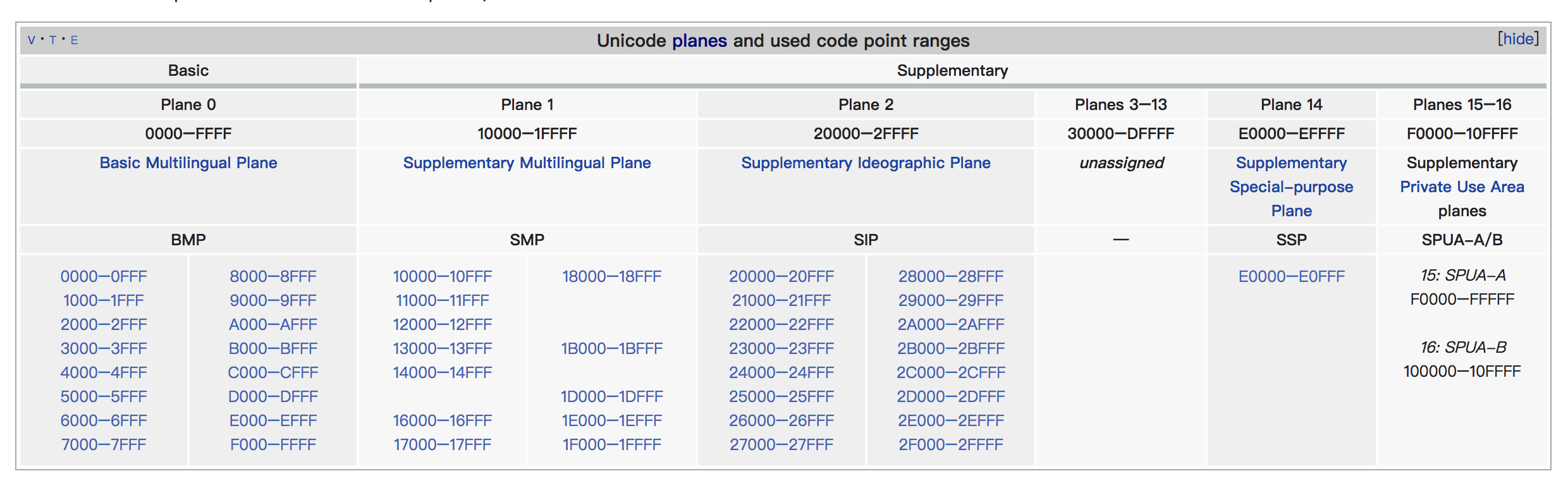
其中第一个Plane(U+0000~ U+FFFF)被称为BMP(Basic Multilingual Plane),包含了几乎所有的常用字符。
剩下的其他Plane(U+10000~ U+10FFFF)被称为supplementary planes(SMP)或者 astral planes,对应的字符通常称为astral symbols。
另: 汉字的 Unicode 码点范围可以参照这里
JavaScript 中的字符表示
转义
在 js 中的字符串中可以使用\u来转义各种 Unicode 字符:
1 | '\u0041'; // A |
如果是astral symbols,在 ES5 中是不能被正常转义的:
1 | Ὂ9; // Ὂ9 |
除非使用他在 js 内部表示的<H,L>形式(下节会描述):
1 | '\uD83D\uDCA9'; // 💩 code point: U+1F4A9 |
不过在 ES6 可以将代码点放到{}中,也能正常转义了:
1 | \u{1F4A9} // 💩 |
内部表示
Internally, JavaScript represents astral symbols as surrogate pairs, and it exposes the separate surrogate halves as separate “characters”. If you represent the symbols using nothing but ECMAScript 5-compatible escape sequences, you’ll see that two escapes are needed for each astral symbol. This is confusing, because humans generally think in terms of Unicode symbols or graphemes instead.
大意: 对于 astral symbols,JavaScript 实际上把它拆成了上下两半(H、L)分别来表示,H 和 L 都是 2 个字节。
H、L 的计算公式:
1 | H = Math.floor((C - 0x10000) / 0x400) + 0xd800; |
因为 astral symbols 的范围是U+010000 → U+10FFFF,故
H的范围就是 0xD800~0xDBFF, 一共 2^10 个字符L的范围就是 0xDC00 ~ 0xDFFF,一共 2^10 个字符
因为astral symbols的范围是U+10000~U+10FFFF,一共 2^20 个字符,所以 H 和 L 结合起来,正巧能表示全部的astral symbols。
例如 “💩”(0x1F4A9),在 javascript 中实际上使用的 0xD83D 和 0xDCA9 来表示的。
实际上上述方法就是 UTF-16 编码的思路,具体参见阮一峰的分享
另外,对于 BMP 区间的码点,js 中会直接将码点转为十六进制形式:
1 | U+4E25 => 0x4E25 |
JavaScript 中的字符串操作
计算 Unicode 字符长度
这个长度指的是人眼直观的长度(即 Unicode 字符个数)。
可以利用 H、L 的取值范围构造正则匹配astral symbols,把他们替换成普通字符,然后计算长度:
1 | var regexAstralSymbols = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g; |
如果使用 ES6 的语法,也可以使用Array.from或者扩散运算符...(二者本质上是同一个东西):
1 | function countSymbols2(string) { |
翻转字符串
此前的做法
1
2
3
4
5
6
7
8function reverse(string) {
return string
.split('')
.reverse()
.join('');
}
reverse('abc'); // 'cba'此方法在处理
astral symbols会出现问题:1
reverse('💩'); // '��'
ES6 提供了好一点的解决方法
1
2
3
4
5
6
7function reverse2(string) {
return Array.from(string)
.reverse()
.join('');
}
reverse2('💩珍香'); // "香珍💩"有一个开源库专门针对字符串反转做了处理: esrever
其他字符串处理方法在面对 Unicode 时的问题
fromCharcode- 可以基于code point创建字符串,但只能处理位于 BMP 区间(U+0000~U+FFFF)的 unicode 字符,会直接截断astral symbols的高位字节。1
2String.fromCharCode(0x0041); // A
String.fromCharCode(0x1f4a9); // '' U+F4A9, not U+1F4A9解决的办法是根据上面计算 H、L 的公式先计算出 H、L,然后再传入
String.fromCharCode:1
2
30x1F4A9 => H: D83D L: DCA9
String.fromCharCode(0xd83d,0xdca9) // "💩"或者直接使用 ES6 的
fromCodePoint:1
String.fromCodePoint(0x1f4a9); // "💩"
String.prototype.charAt(position)对于astral symbols获取的只是 H 或者 L 的部分:1
2'💩'.charAt(0); // '\uD83D'
'💩'.charAt(1); // '\uDCA9'String.prototype.charCodeAt(position),与charAt类似,对于astral symbols获取的只是 H 或者 L 的数字形式:1
2'💩'.charCodeAt(0); // 0xD83D
'💩'.charCodeAt(1); // 0xDCA9取而代之应该使用
codePointAt:1
'💩'.codePointAt(0); // 0x1F4A9
正则表达式与 Unicode
匹配 BMP 区间字符
可以直接使用转义形式的正则来匹配 BMP 区间字符:
1 | /\u0061/.test('a'); // true |
匹配 astral symbol
直接用对应的代码点构成的正则是不能匹配astral symbol的:
1 | /\u{1F4A9}/.test('💩'); // false |
由于astral symbol在 js 中是由 H/L 分开表示,.点号也不能匹配astral symbol:
1 | /foo.bar/.test('foo💩bar') // fasle |
如果只从代码点的角度出发,这里是一个完整的匹配 Unicode 的正则(之后会介绍 ES6 新增的u修饰符):
1 | // match BMP、astral symbol H/L pair、 lone H/L |
如果注意到上面正则的第一个部分是分为了两段: \0-\uD7FF和\uE000-\uFFFF,这是因为BMP内的U+D800到U+DFFF是一个空段,期间的代码点没有映射到任何字符。实际上UTF-16编码正是利用的这个空段来映射astral symbols的。
范围匹配与 Unicode
正则表达式中经常会用到范围匹配:
1 | /[a-c]/.test('a') // true |
但是这种方法在遇到 Unicode 字符时可能会出问题:
1 | /[💩-💫]/; |
因为上面的正则表达式等价于:
1 | /[\uD83D\uDCA9-\uD83D\uDCAB]/; |
-前后分别是两个字符的 H、L 部分,这个表达式其实是在匹配:
\uD83D一个 H\uDCA9-\uD83D这里是出错的原因,因为左边的值比右边大\uDCAB一个 L
解决办法 - 使用 ES6 新增的u正则修饰符,后面会描述。
数量匹配与 astral symbol
正则中可以用一些量词来匹配某个选项多次,如*,+, ?, and {n}, {n,}, {n,m},这些在处理 BMP 字符时没问题:
1 | /a{2}/.test('aa') //true |
但是遇到astral symbol也会出问题:
1 | /💩{2}/.test('💩💩') // false |
原因是因为这些正则表达式实际上会表达成<H,L>的形式:
1 | /\u{1F4A9}{2}/ => /\uD83D\uDCA9{2}/ // 其实匹配的是 H+L*2 |
一个可行的解决方案是直接采用对应的<H,L>形式来写正则:
1 | /(\uD83D\uDCA9){2}/.test('💩💩'); // true |
或者使用u正则修饰符。
u 修饰符
阮一峰的ES6 入门中是这样描述的:
ES6 对正则表达式添加了 u 修饰符,含义为“Unicode 模式”,用来正确处理大于\uFFFF 的 Unicode 字符。也就是说,会正确处理四个字节的 UTF-16 编码。
这就表示我们可以直接用u修饰符加上原始的代码点就能匹配所有的 Unicode 字符了。
单个字符匹配
1 | /\u0061/u.test('a') // true |
范围匹配
1 | /[\uD83D\uDCA9-\uD83D\uDCAB]/u.test('\uD83D\uDCA9') // true . match U+1F4A9 |
数量匹配
1 | /💩{2}/u.test('💩💩'); // true |
其他
反向匹配标识(如/[^a]/以及/\S/、/\D/)在遇到astral symbols都会出现问题,u修饰符也会解决:
1 | /^[^a]$/.test('💩') // false |
对 input、textarea 的 patten 属性影响
幸运的是u修饰符默认是附加在了pattern属性上的:
1 | <style> |
兼容性
u flag 的注意事项
看了以上的描述,很容易让人觉得u flag是万能的。 不过在处理遗留代码时还是要注意一下的,因为u flag会假定正则表达式里的\u后面接的是一个合法的Code Point,如果不是的话就会报错:
1 | /\a/.test('a') // true |
上面的\a意图把a转义,实际上当然是不起作用的,等效于/a/,不过却不会报错的。 但是加上u flag后,会直接判定非法。
UTF8 编码
Unicode 只是一个字符集,每个代码点真正在存储前是需要进行编码的。 在 utf-8 编码中,最核心的就是一个对应表:
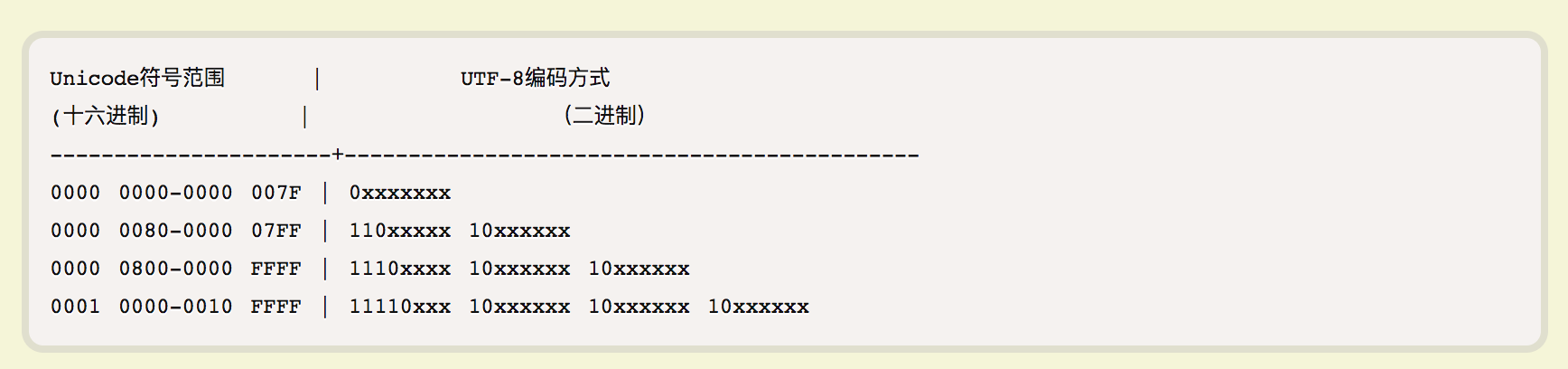
可以看到不同范围的代码点在编码后可能使用 1~4 个字节表示。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于 n 字节的符号(n > 1),第一个字节的前 n 位都设为 1,第 n + 1 位设为 0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
举个例子:
“严”的代码点是U+4E25,根据上图发现在 utf-8 编码后有 3 个字节。具体编码步骤见下图(纯手绘 😄):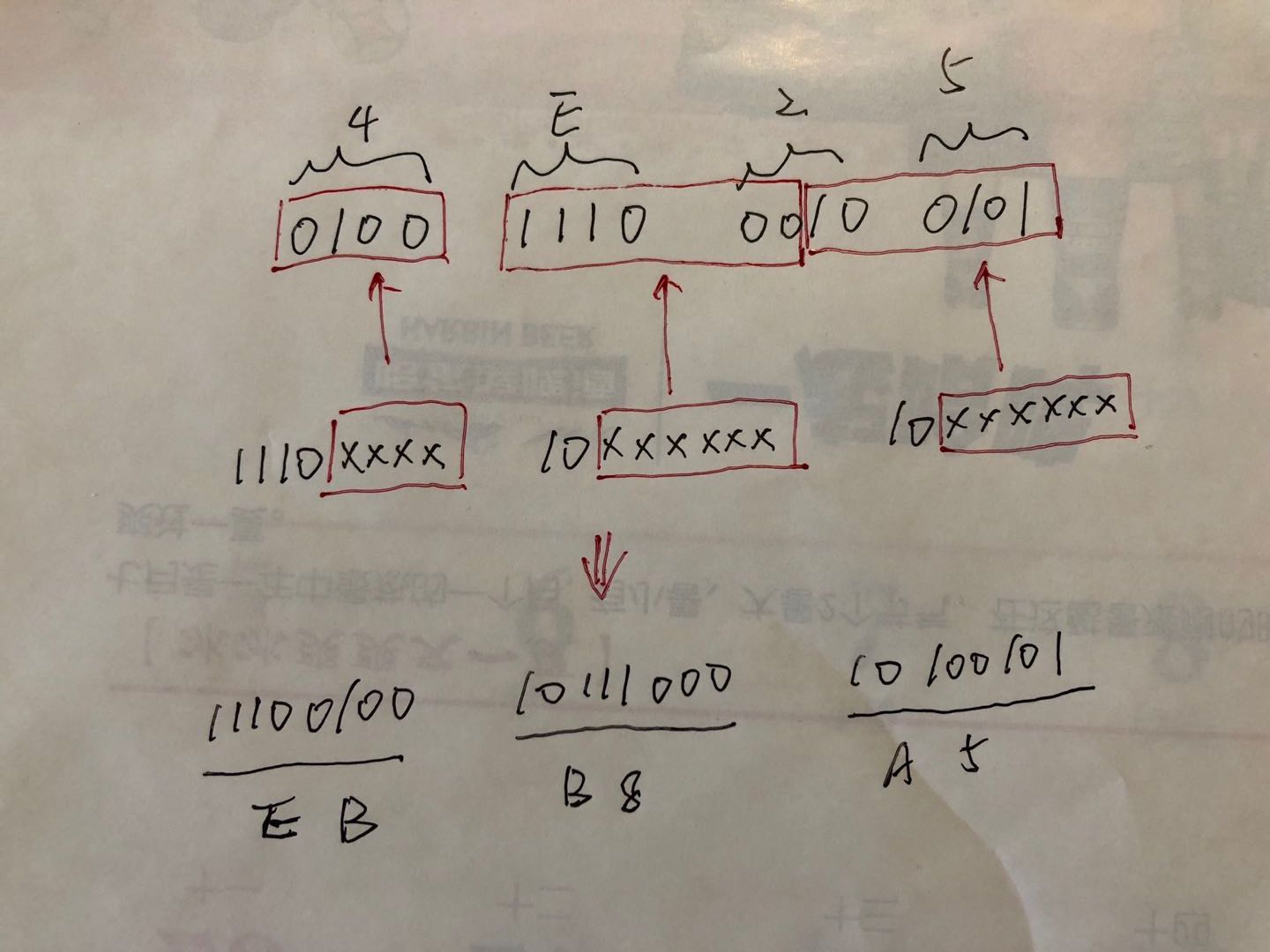
即”严”在 utf-8 编码后是用0xEBB8A5来表示的。
一个细节:映射表里后面字节的10是为了处于任何一个字节时,都知道当前是一个单字节符号还是多字节符号,如果是多字节符号,那么什么接下来的多少个字节表示一个完整的符号结束:
- 如果当前字节的第一为是
0,那么这个字节必然就是一个单字节符号; - 如果当前字节的前两位是
11,那么当前字节必然是一个多字节符号的第一个字节; - 如果前两位是
10,那么当前字节必然是一个多字节符号的某个中间字节,并且直到接下来的某个字节前两位不是10了,这个多字节符号才结束。
Unicode 字符转为 utf8 编码后的字节长度计算
- 利用encodeURIComponent转为 utf8 编码:
1
encodeURIComponent('💩') // "%F0%9F%92%A9"
1
2
3
4
5
6
7
8
9
function utf8Length(charactor){
// Matches only the 10.. bytes that are non-initial characters in a multi-byte sequence.
const m = encodeURIComponent(charactor).match(/%[89ABab]/g);
return (m ? m.length : 0) + 1;
}
utf8Length("💩") // 4
utf8Length("严") // 3
utf8Length("a") // 1
- 直接通过代码点 Code Point 的范围计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
function utf8Length(charactor) {
codePoint = charactor.codePointAt(0);
// NOT charCodeAt,因为其只能返回0~FFFF的整数,见MDN
// charCodeAt: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/charCodeAt
// codePointAt: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/codePointAt
if (codePoint <= 0x007f) {
return 1;
} else if (codePoint <= 0x07ff) {
return 2;
} else if (codePoint <= 0xffff) {
return 3;
}
return 4;
}
utf8Length("💩") // 4
utf8Length("严") // 3
utf8Length("a") // 1
Unicode 字符串转 utf8 编码后的字节长度计算
要注意的是 String 的 length 属性表示的是 utf-16 编码后的字节长度,同理string[i]表示 i 这个位置上的一个 2 字节的 UTF-16 编码字符。 如果 i 位置上是一个 2 字节 UTF-16 编码字符无法表示的astral symbols,那么就会显示乱码,因为此时string[i]指向的是 H 或 L,必须i和i+1两个位置联合起来才能完整表示。
1 | '💩'.length; // 2, 注意上面我们计算的它在utf8编码下使用了4个字节 |
知道这一点后,我们有 2 种方法来计算任一字符串转为 utf8 编码后的字节长度:
小心翼翼的处理
astral symbols的H、L部分 ,一步一个脚印:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25function strUtf8Length(str) {
let index = 0;
let total = 0;
while (index < str.length) {
const charCode = str.charCodeAt(index);
console.log(`charCode:`, charCode.toString(16));
if (0xd800 <= charCode && charCode <= 0xdbff) {
// 处于astral symbols的H区域,说明当前str[index]与str[index+1]才能构成一个完整的Unicode字符
total += utf8Length(str.slice(index, index + 2));
index += 2;
} else {
// 处于BMP区(U+0000~U+FFFF),说明UTF-16编码的单独str[index]就能表示一个完整的Unicode字符
total += utf8Length(str[index]);
index += 1;
}
}
return total;
}
console.log(strUtf8Length('💩')); // 4
console.log(strUtf8Length('严')); // 3
console.log(strUtf8Length('a')); // 1
console.log(strUtf8Length('💩严a')); //8ES6 中的
for...of会替我们处理上面的那些重复细节1
2
3
4
5
6
7
8
9
10
11
12function strUtf8Length2(str) {
let total = 0;
for (const symbol of str) {
total += utf8Length(symbol); // symbol表示每一个单独的Unicode字符
}
return total;
}
console.log(strUtf8Length2('💩')); // 4
console.log(strUtf8Length2('严')); // 3
console.log(strUtf8Length2('a')); // 1
console.log(strUtf8Length2('💩严a')); //8