ES5 中的字符操作
es5 中提供了一些跟字符相关的操作,在某些需要精细化处理字符串的场所可能有帮助。
字符转义
可以使用\u来转义各种十六进制数为相应字符:
1 | '\u0041'; // A |
fromCharCode、charCodeAt、charAt、length
String.fromCharcode- 可以基于『代码点』创建字符串,暂时可以把『代码点』理解为就是一串十六进制数1
2String.fromCharCode(0x0041); // A
String.fromCharCode(0x4e25); // 严String.prototype.charAt(position)获取字符串在特定位置的字符1
2'ABCDE'.charAt(2); // C
'万几皮'.charAt(2); // 皮String.prototype.charCodeAt(position),与charAt类似,只不过是获取在特定位置的那个字符的『代码点』。同时可以很容易看出来这个方法是fromCharCode的反向操作。1
2
3
4
5'ABCDE'.charCodeAt(2).toString(16); // 0x0043
'万几皮'.charCodeAt(2).toString(16); // 0x76AE
// 验证反向操作
String.fromCharCode('万几皮'.charCodeAt(2)); // "皮"length属性很熟悉了,就是计算长度呗1
2'ABCDE'.length; // 5
'万几皮'.length; // 3
遇到 Unicode 字符时遇到的问题
到目前为准都没什么问题,配合String.prototype上的各种工具方法,可以处理各种各样常见字符串操作。不过随着emoji表情的盛行,慢慢就会发现已有的工具出现各种各样的问题。
fromCharCode、charCodeAt 的反向操作
先看看上面的反向操作还能不能工作:
1 | String.fromCharCode('💩'.charCodeAt(0)); // "�" |
结果是乱码???
那么再看看length:
1 | '💩'.length; // 2 |
因吹丝停,看来遇到了一些奇怪的问题,如果继续尝试,可以发现一些其他的『BUG』:
翻转字符串
翻转字符串可能是一个比较常见的字符串操作,通常可能有一个如下的工具函数:
1 | function reverse(str) { |
如果用来操作表情呢?
1 | reverse('💩'); |
感觉好像表情被拆散成了 2 个奇怪的字符。
在正则匹配时,也有奇怪的事情发生
正则匹配
范围匹配
正则表达式中经常会用到范围匹配:
1 | /[a-c]/.test('a') // true |
但是这种方法在遇到表情时可能会出问题:
1 | /[💩-💫]/; |
囧,竟然直接就报错了。。
数量匹配
正则中可以用一些量词来匹配某个选项多次,如*,+, ?, {n}, {n,}, {n,m},这些在处理『常见普通』字符时没问题:
1 | /a{2}/.test('aa') //true |
不出意料,遇到表情也会出问题:
1 | /💩{2}/.test('💩💩'); // false |
种种奇怪的现象都表明,js 在处理 emoji 时有问题,而这种现象在普通英文字母和汉字上不会存在,而脑海里跟 emoji 最相关的就是 Unicode 了,看来有必要了解下 Unicode。那 Unicode 到底是个啥?
Unicode 简介
Unicode 是一个字符集(注意不是编码方式,时不时听到有人说 Unicode 编码,实际上是不正确的说法),它把目前世界上所有字符包含在内了。每个符号都与一个称为代码点(Code Point)的十六进制数对应,代码点通常有一个U+前缀,例如:
1 | U+0041 => A |
codepoints上可以浏览各种各样的 Unicode 字符,我们 💩 先生的代码点是U+1F4A9~~~
Code Point 的取值范围是U+0000~U+10FFFF,大约有 110 万个。 为了好组织,所有Code Point被分为了 17 个Plane,每个Plane中大约包含 65K 个Code Point。 见维基百科
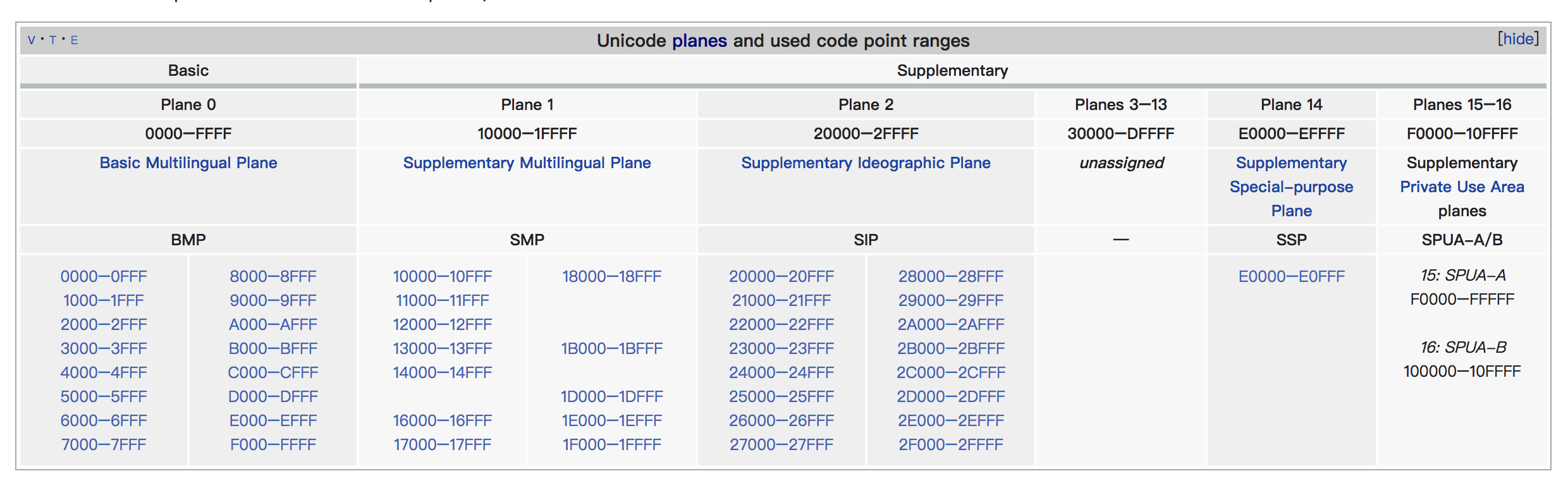
其中第一个Plane(U+0000~ U+FFFF)被称为BMP(Basic Multilingual Plane),包含了几乎所有的常用字符。
剩下的其他Plane(U+10000~ U+10FFFF)被称为supplementary planes(SMP)或者 astral planes,对应的字符通常称为SMP字符。
另: 汉字的 Unicode 码点范围可以参照这里
关于 Unicode 先介绍这么多,我们关心的是,这个跟上面遇到的那些 BUG 有什么关系呢?这就要从 js 内部对字符的表示说起了。
js 内部的字符表示
上面说到 Unicode 只是字符集,在计算机内部不会直接存储字符集中的字符,而是会通过某种编码把它转换为一个个字节。对于大部分常见的字符,都是用 2 个字节表示的;而对于 emoji 表情,可能有人已经猜到了,是用 4 个字节表示的。
更具体的来说: 对于SMP字符,JavaScript 实际上把它拆成了上下两半(H、L)分别来表示,H 和 L都是 2 个字节的。
H、L 的计算公式:
1 | H = Math.floor((C - 0x10000) / 0x400) + 0xd800; |
因为 SMP字符 的范围是U+010000 → U+10FFFF,故
H的范围就是 0xD800~0xDBFF, 一共 2^10 个字符L的范围就是 0xDC00 ~ 0xDFFF,一共 2^10 个字符
貌似很巧合的是:因为SMP字符的范围是U+10000~U+10FFFF,一共 2^20 个字符,所以 H 和 L 结合起来,正巧能表示全部的SMP字符。而 BMP 中U+D800到U+DFFF是一个空段,里面不对应任何字符。
例如对于”💩”(0x1F4A9),通过上面公式计算可以得到H = 0xD83D、L = 0xDCA9,也就是说 js 内部会使用0xD83D和0xDCA9一共 4 个字节来表示它。
同时,对于 BMP 区间的代码点,js 中会直接将码点转为十六进制形式的 2 字节:
1 | U+4E25 => 0x4E25 |
我们上面碰到的所有SMP字符BUG 都是因为 H、L 导致,理解了这个也就知道该如何解决了。 不过在想办法解决它之前,我们来正面回答一下,js 内部是使用什么编码方式处理字符的?
js 中的字符编码
好吧,这块的知识是从阮老师的这篇博客了解到的,我直接说结论吧。
js 使用的其实是UCS-2编码,由于这种编码被整合进了UTF-16编码,也可以认为 js 使用的是UTF-16编码处理字符。不过在细节上这两种编码还是有一些区别的:
UTF-16 编码对于基本平面的字符占用 2 个字节,对于辅助平面的字符占用 4 个字节; 也就是说:对于”💩”,UTF-16会认为它是一个字符,占用 4 个字节。
而 UCS-2 认为所有字符都是 2 个字节,而对于辅助平面的字符例如 💩,就比较尴尬了,UCS-2 认为它是 2 个字符(H 和 L),每个字符占 2 个字节。
UTF-16 编码
再稍微说一下UTF-16编码,知道了 H、L,理解UTF-16就很容易了。上面提到它是一种变长的编码,结果可能是 2 个字节,也可能是 4 个字节。
具体来说:
- 如果是 BMP 字符,那么其代码点就是编码结果,如
U+4E25 => 0x4E25 - 如果是 SMP 字符,那么计算 H、L,H 和 L 拼凑起来的 4 个字节,就是最终结果,如
0x1F4A9的结果就是0xD83DDCA9
es5 中处理SMP字符
- length:💩 的
length为 2 应该可以理解了,实际上它是 H、L 两个字符,可以看出length的结果并不是肉眼所看到的字符个数。 charCodeAt: 如果猜测的没错,对于 💩,可以分别得出charCodeAt(0)和charCodeAt(1),它们的结果正好就是 H 和 L:1
2'💩'.charCodeAt(0).toString(16); // 0xD83D
'💩'.charCodeAt(1).toString(16); // 0xDCA9fromCharcode- 只能处理位于 BMP 区间(U+0000~U+FFFF)的BMP字符,会直接截断SMP字符的高位字节:1
2String.fromCharCode(0x0041); // A
String.fromCharCode(0x1f4a9); // '' U+F4A9, not U+1F4A9解决的办法是根据上面计算
H、L的公式先计算出H、L,然后再传入String.fromCharCode:1
String.fromCharCode(0xd83d, 0xdca9); // "💩"
数量匹配
SMP字符: 匹配失败的原因是SMP字符被打散成了 H、L1
/💩{2}/ => /\uD83D\uDCA9{2}/ // 其实匹配的是 H+L*2
一个可行的方案是直接采用括号包裹对应的
<H,L>来写正则1
/(\uD83D\uDCA9){2}/.test('💩💩'); // true
范围匹配
SMP字符: 报错的原因也是H、L:1
/[💩-💫]/ => /[\uD83D\uDCA9-\uD83D\uDCAB]/
上面的
\uDCA9-\uD83D左边的值比右边大,导致报错。一个很挫的解决方案是提供他们的 H、L 公共范围并精简表达式:1
2/\uD83D[\uDCA9-\uDCAB]/.test('💩') // true
/\uD83D[\uDCA9-\uDCAB]/.test('💫') // true这种方法的缺点也很明显,对于两个跨度很大的
SMP字符,需要精心的分段,稍不留神就会出错:1
2
3
4
5/[𐄑-💫]/
=>
/\uD800[\uDD11-\uDFFF]|[\uD801-\uD83C][\uDC00-\uDFFF]|\uD83D[\uDC00-\uDCAB]/.test('💪') // truereverse函数:遇到SMP字符会直接把 H、L 颠倒,而每个独立的 H、L 都是『乱码』,只有二者结合在一起才有意义。如果要解决问题,需要知道在碰到 H 的时候,下一个字符会是 L,不要把二者颠倒就行。不过esrever提供了一个更巧妙的思路:先将 H、L 颠倒一次,然后再执行一次普通的 reverse 即可:
1
2
3
4
5
6
7
8
9
10
11
12
13const regexSurrogatePair = /([\uD800-\uDBFF])([\uDC00-\uDFFF])/g;
function reverse(string) {
const tempStr = string.replace(regexSurrogatePair, '$2$1');
return tempStr
.split('')
.reverse()
.join('');
}
console.log(reverse('abcd')); // dcba
console.log(reverse('💩万几皮')); // 皮几万💩
ES6 中如何解决 Unicode 问题
在 es5 中处理 SMP 字符需要时刻记住 H、L 的存在,既麻烦又容易出错。好在 es6 中新增了一系列特性来专门处理 SMP 字符,下面逐一说明。
字符转义
es5 中的\u字符转义不能正确处理 SMP 字符,例如 😄(U+1F604, H=0xD83D L=0xDE04):
1 | '\u1F604'; // "ὠ4" '\u1F60' + '4' |
除非使用 H、L 的形式:
1 | '\uD83D\uDE04'; // 😄 |
es6 中提供了更好的方法,使用{}包裹代码点即可:
1 | '\u{1f604}'; // 😄 |
codePointAt
charCodeAt只能正确获取 BMP 字符的代码点,对于 SMP 字符只能获取 H 或 L;es6 中新增的codePointAt,他能统一处理好 BMP 以及 SMP 字符:
1 | '😄'.codePointAt(0).toString(16); // 0x1f604 |
fromCodePoint
同样的,fromCharcode也只能正确处理 BMP 字符; es6 新增的fromCodePoint解决了这个问题:
1 | String.fromCodePoint(0x1f604); // 😄 |
正则匹配
ES6 对正则表达式添加了u修饰符,含义为“Unicode 模式”,用来正确处理大于U+FFFF的 SMP 字符。
也就是说:我们可以直接用u修饰符加上原始的代码点或字符就能正确匹配所有的 Unicode 字符了。
单字符匹配
若没有u修饰符,即使使用 es6 中的字符转义也不能正确匹配 SMP 字符:
1 | /\u{1f604}/.test('😄'); // false |
由于 H、L 的存在,即使.点号也不能匹配 SMP 字符:
1 | /foo.bar/.test('foo😄bar'); // false |
使用u修饰符可以处理这个问题:
1 | /\u{1f604}/u.test('😄'); // true |
范围匹配
上面已经提到过,在 es5 中 SMP 范围匹配会直接报错:
1 | /[💩-💫]/; // // Uncaught SyntaxError: Invalid regular expression: /[💩-💫]/: Range out of order in character class |
u在这里扮演了救世主:
1 | // 💩 0x1f4a9 => H=0xD83D ,L=0xDCA9 |
直接使用 H、L 的形式来写正则也不会报错了:
1 | /[\uD83D\uDCA9-\uD83D\uDCAB]/u.test('💩') // true |
数量匹配
复习一下 es5 在数量匹配 SMP 时的问题:
1 | /😄{2}/.test('😄😄'); // false |
继续看看u的作用:
1 | /😄{2}/u.test('😄😄') // true |
表单校验中的 pattern
在表单校验中,input元素有一个规则属性是pattern,可以给它设置一个正则表达式,若表单项的值匹配了pattern,会默认添加一个valid的伪类,反之添加invalid伪类。
1 | <style> |
1 | <form action=""> |
幸运的是,不需要我们做什么 hack 操作,u修饰符已经默认附加在了 pattern 上:
1 | <form action="" class="form"> |
兼容性
u修饰符的兼容性参考test-RegExp_y_and_u_flags
Array.from
可能有时候需要计算字符串中的『字数』(即肉眼见到的字符数),例如界面提示用户输入了多少字。如上所述,这个时候不能简单的使用length属性,因为对于一个SMP字符它会返回 2.
在 es5 中我们可以这么做:
1 | var regexSMP = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g; |
es6 中借助Array.from或者扩散运算符...可以更简便,他会帮助我们处理好 Unicode 字符:
1 | function countSymbols2(string) { |
同样reverse函数也能用Array.from:
1 | function reverse2(string) { |