前言
前阵子在项目里用到了二维码的生成,当时直接拿了第三方库来做,觉得很神奇,恰好这两天有一点时间,就学习了一波底层原理。学习的过程中参考了好几个博客,不同的博客在不同的细节上写的比较好,趁着还没忘就趁热打铁记录在博客里。
二维码本质上是对字符串的编码规则,最终转换成二进制串。不过在这个串里加了各种辅助信息以及纠错信息,最终绘制到页面上时就成了眼睛看到的样子。
基础知识
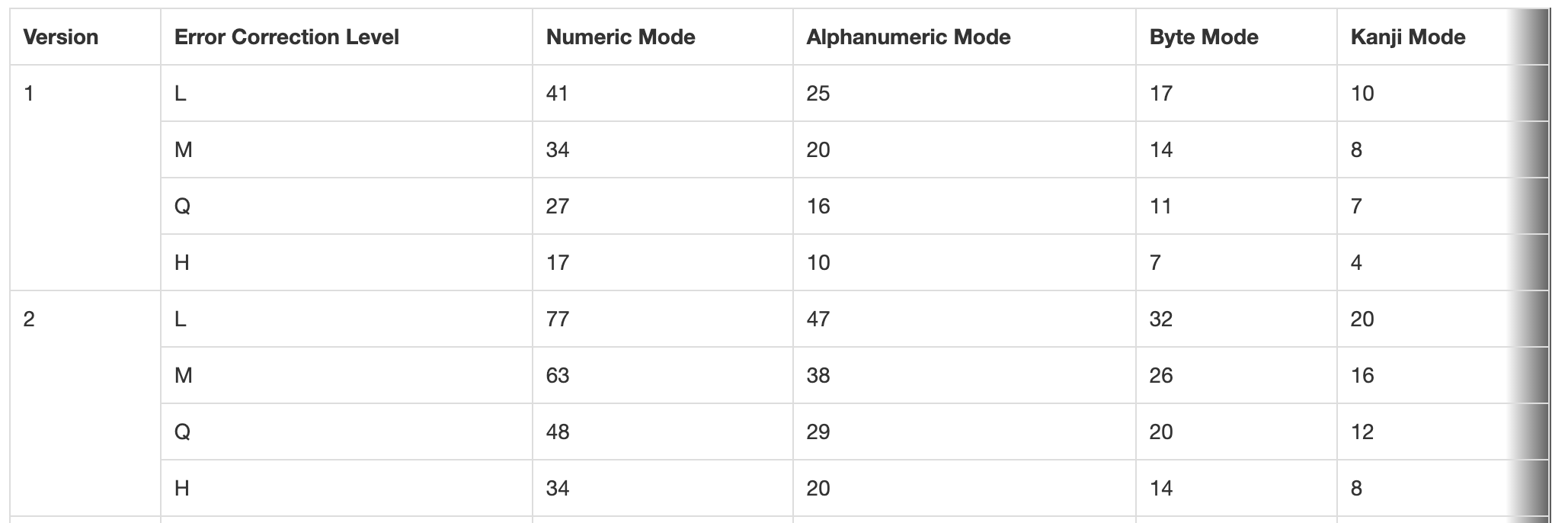
二维码一共有40个尺寸(也可以称为版本、Version)。Version 1是21 x 21的矩阵,Version 2是 25 x 25的矩阵。每增加一个version,长宽就增加 4,公式是:
1 | (V - 1) * 4 + 21; |
最高版本是40,所以是177 x 177的正方形。 每个1x1都是一个小方块,黑色表示 1,白色表示 0。所以通过个人微信二维码的版本是多少呢?🙃

二维码图案分为很多子部分,如下:

- 功能区域,不包含实质性的信息,只是一些辅助作用
- 位置探测区域:一共有 3 个,用于决定二维码的哪一边应该朝上,这样我们不管从什么方向扫码都不会混乱了。它是一个固定大小的回字

- 位置探测图形分隔符:将位置探测区域围起来的固定宽度 1 的白色“围栏”
- 定位图形: 也叫
Timing Patterns,是两根黑白相间的长条,每一根的头尾都是黑色。主要用来协助机器扫描的 - 校正图形: 是比较小的回字,用于校正
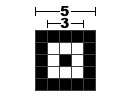
不同的version拥有不同数量的校正图形,位置也是不一样,这个在后面会专门说。
- 位置探测区域:一共有 3 个,用于决定二维码的哪一边应该朝上,这样我们不管从什么方向扫码都不会混乱了。它是一个固定大小的回字
编码区,实际存储有意义数据的区域,包含 3 个子部分
- 格式信息:所有
version的二维码都有,存放二维码的容错级别+数据掩码+二者的纠错码 - 版本信息:表示二维码的
version,version >=7才会绘制这个区域。(其实肉眼数格子也可以知道版本信息 😆 ) - 数据和纠错码:存储真正的数据,同时由于纠错码的存在,使得即使二维码污损了一部分也可以读取. 整个灰色区域都用来存放此部分数据。二维码支持 4 种级别的纠错:
- 格式信息:所有
| 纠错级别 | 恢复能力 |
|---|---|
| L | Recovers 7% of data |
| M | Recovers 15% of data |
| Q | Recovers 25% of data |
| H | Recovers 30% of data |
纠错级别越高,恢复能力越强,代价是能存储的有效数据越少,因为纠错码的占比会越高。
接下来主要介绍核心的数据和纠错码部分。
编码步骤
步骤是先对源数据进行编码,然后依据编码结果计算得到纠错码,最后再在结尾加上一些用于补齐的字节就 ok 了。
源数据编码
编码模式(模式指示符)
类似于utf8编码,这部分也就是给定一个字符串,然后将其编码成一串二进制数。支持的编码模式有:
- 数字编码(
Numeric Mode): 只支持数字 0~9 的编码 - 字符编码(
Alphanumeric Mode):支持包含数字、大写的A-Z(不包含小写)、以及$ % * + – . / :和空格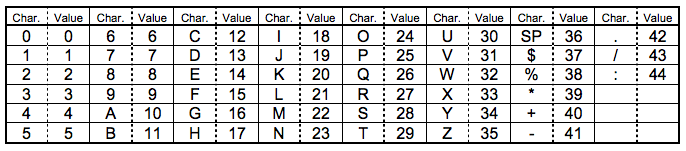
- 字节编码(
Byte Mode): 支持0x00~0xFF内所有的字符 - 日文编码(
Kanji Mode): 只能支持0x8140~0x9FFC、0xE040~0xEBBF的字符,可以在这里找到 ECI mode: 主要用于特殊的字符集。并不是所有的扫描器都支持这种编码Structured Append mode: 用于混合编码,也就是说,这个二维码中包含了多种编码格式FNC1 mode: 这种编码方式主要是给一些特殊的工业或行业用的。比如 GS1 条形码之类的。
每种模式都由 4 位二进制的模式指示符确定:
| Mode Name | Mode Indicator |
|---|---|
| Numeric Mode | 0001 |
| Alphanumeric Mode | 0010 |
| Byte Mode | 0100 |
| Kanji Mode | 1000 |
| ECI Mode | 0111 |
例如字符串123,就可以使用Numeric Mode;而HELLO WORLD需要用Alphanumeric Mode;Hello world需要使用Byte Mode.
版本、纠错级别确定
首先依据源字符串可以知道应该采用哪种编码方式,然后需要先确定纠错级别,最后不同版本在此纠错级别+编码方式下的数据容量是不同的。我们只需找到最小的能容纳所有数据的那个版本即可。
举例来说:字符串 HELLO WORLD包含 11 个字符,通过上面的介绍得知,它应该使用字符编码Alphanumeric Mode,如果设定纠错级别是Q,通过查表得知1-Q可以容纳 16 个字符,那么最低就可以使用版本 1:
如果是字符串HELLO THERE WORLD(17 个字符),那么最低版本就只能选 2 了。
另外,可以推断,二维码是存在数据容量上限的,它应该是40-L的容量:
| Encoding Mode | Maximum number of characters a 40-L code can contain in that mode |
|---|---|
| Numeric | 7089 characters |
| Alphanumeric | 4296 characters |
| Byte | 2953 characters |
| Kanji | 1817 characters |
也就是说,单纯存储数字的话,可以存 7089 个;只存大写字母的话,可以存大约 4k 个。
字符计数指示符
是一串二进制数字,表示源字符串的字符个数。字符计数指示符必须放在模式指示符之后。此外,字符计数指示符有特定的位长,具体取决于二维码的版本和编码模式:
| 单位 bits | Versions 1 ~ 9 | Versions 10 ~ 26 | Versions 27 ~ 40 |
|---|---|---|---|
| Numeric mode | 10 | 12 | 14 |
| Alphanumeric mode | 9 | 11 | 13 |
| Byte mode | 8 | 16 | 16 |
| Kanji mode | 8 | 10 | 12 |
具体步骤是:计算原始输入文本的字符数,将其转为二进制数字。根据版本和编码模式找到对应的位长,不够位长的在前面加 0 补齐。
例如 HELLO WORLD, 版本号为 1,则字符计数指示符需要 9 bits.HELLO WORLD的字符数为 11,转为二进制1011,不够 9 位,需要补上 5 个 0,最终结果是000001011
那么针对HELLO WORLD,我们目前获得的二进制串是0010 000001011,0010是模式指示符Alphanumeric Mode。
字符串编码
这一步就是利用编码模式对源字符串进行编码,我们仍以HELLO WORLD为例,使用Alphanumeric Mode。
- 将字符以 2 为间隔分组,得到
(H,E)、(L,L)、(O, )、(W,O)、(R,L)、(D) - 在字母索引表中找到对应的
value,得到(17,14)、(21,21)、(24,36)、(32,24)、(27,21)、(13) 对于每组数字,将第一个数字乘以 45 加上第二个数字(最大结果 2024),得到的结果再转为长度为 11 的二进制串,长度不足的前面补 0。例如
(17,14) => 17*45+14=779 => 1100001011 => 01100001011。如果最后一组是单个字符,则用 6 位表示就行。最终得到结果:1
01100001011 01111000110 10001011100 10110111000 10011010100 001101
追加到模式指示符和字符计数指示符之后,得到结果:
1 | 0010 000001011 01100001011 01111000110 10001011100 10110111000 10011010100 001101 |
后续的补齐
在给定版本和纠错级别后,源数据的编码结果是一个固定长度的二进制串,如果在上一步的结果没有达到这个长度,需要进行一些补齐操作。
例如1-Q下,源数据编码结果需要是13个字节,也就是104位:
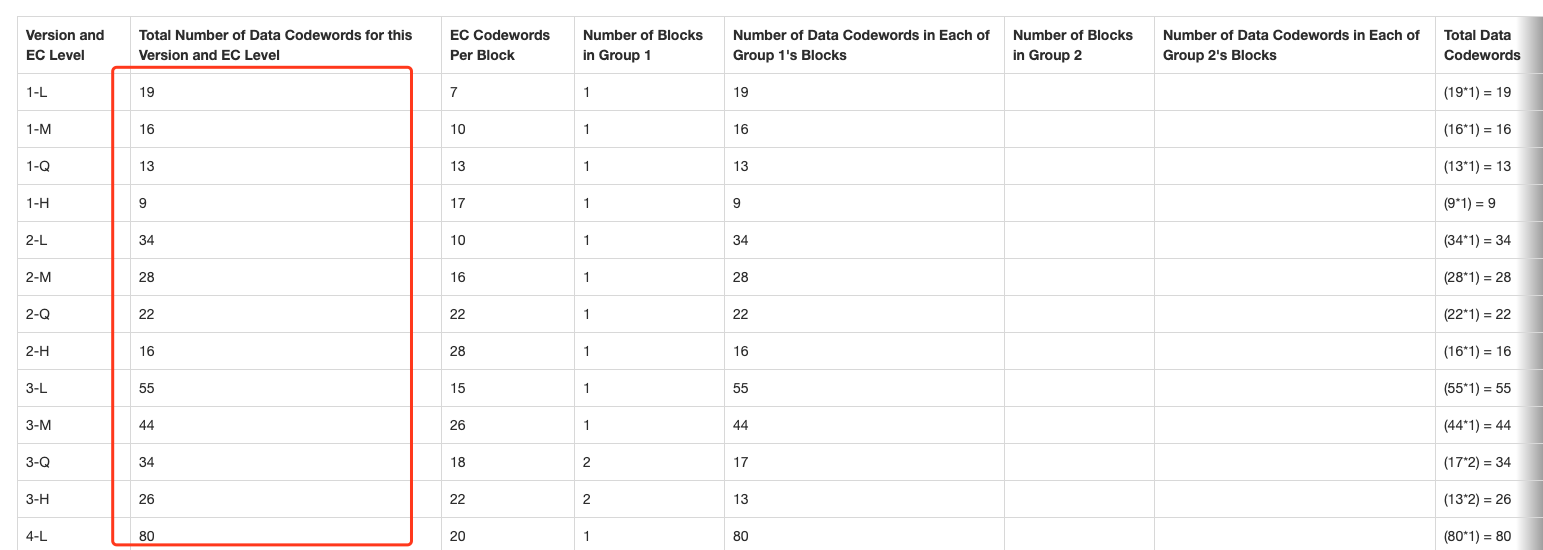
而HELLO WORLD在上一步之后的二进制串是 74 位,所以需要补齐。
- 末尾追加至多
4个0的终止符0000 - 末尾补更多的
0直到8的倍数,例如上面74+4=78,就需要再补 2 个 0:00 - 如果长度还没有达到目标,末尾重复添加固定的补齐码
11101100 00010001直到满足长度。例如上面就需要添加11101100 00010001 11101100
以上就是源数据编码了,HELLO WORLD的编码结果由以下各部分组成:
| 模式指示符 | 字符计数指示符 | 字符串自身编码 | 终止符 | 补齐到 8 的倍数 | 补齐码 |
|---|---|---|---|---|---|
0010 |
000001011 |
01100001011 01111000110 10001011100 10110111000 10011010100 001101 |
0000 |
00 |
11101100 00010001 11101100 |
纠错码生成
根据源数据编码结果可以计算得到纠错码,使用的是Reed-Solomon纠错算法。这个比较复杂我没怎么看,这里只以网上的例子作为示范。
纠错码也和版本和纠错级别有关系,参考这个纠错表。
纠错表中包含group 1和group 2,每个group又包含至多 2 个block。源数据编码结果必须被分割成多达两个group,并且在每个group内也需要进一步分成block,在这个过程中源数据编码被顺序地分解。
以5-Q为例:

可以知道的信息是:
- 源数据编码结果的总长度是 62 个字节
- 纠错码被分为
group 1与group 2,两个group内都含有 2 个block - 每个
block包含 18 个字节的纠错码,所以纠错码的总长度是18*4 = 72个字节 group 1内的每个block,包含 15 个字节的源数据,以及 18 个字节的纠错码。也就是说源数据编码的前 15 个字节会放到group 1->block 1中,第 16~30 这 15 个字节会放到group 1->block 2中group 2内的每个block,包含 16 个字节的源数据,以及 18 个字节的纠错码
另外细心点可以看的出来:给定版本后,源数据编码总长度+纠错码总长度是固定的,例如版本 5 就是 134 个字节。
至于每个block内部如何根据源数据编码计算得到纠错码,我也不看懂就不说了,只贴一下结果(这里的源数据编码不是HELLO WORLD的哈~,从哪来的我也母鸡),由于二进制串太长,统一转成了 10 进制:
| Group | Block | 源数据编码 | 此 block 的纠错码 |
|---|---|---|---|
| 1 | 1 | 67 85 70 134 87 38 85 194 119 50 6 18 6 103 38 |
213 199 11 45 115 247 241 223 229 248 154 117 154 111 86 161 111 39 |
| 1 | 2 | 246 246 66 7 118 134 242 7 38 86 22 198 199 146 6 |
87 204 96 60 202 182 124 157 200 134 27 129 209 17 163 163 120 133 |
| 2 | 1 | 182 230 247 119 50 7 118 134 87 38 82 6 134 151 50 7 |
148 116 177 212 76 133 75 242 238 76 195 230 189 10 108 240 192 141 |
| 2 | 2 | 70 247 118 86 194 6 151 50 16 236 17 236 17 236 17 236 |
235 159 5 173 24 147 59 33 106 40 255 172 82 2 131 32 178 236 |
到这一步还没有结束,最终的编码结果并不是这些串顺序相连,而是交替连接。如何交替呢,规则如下:
不论数据码还是纠错码,把每个块的第一个字节先拿出来按顺度排列好,然后再取每个块的第二个字节,如此类推。
具体操作如下,首先对于源数据编码,先摆放好:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| block 1-1 | 67 | 85 | 70 | 134 | 87 | 38 | 85 | 194 | 119 | 50 | 6 | 18 | 6 | 103 | 38 | |
| block 1-2 | 246 | 246 | 66 | 7 | 118 | 134 | 242 | 7 | 38 | 86 | 22 | 198 | 199 | 146 | 6 | |
| block 2-1 | 182 | 230 | 247 | 119 | 50 | 7 | 118 | 134 | 87 | 38 | 82 | 6 | 134 | 151 | 50 | 7 |
| block 2-2 | 70 | 247 | 118 | 86 | 194 | 6 | 151 | 50 | 16 | 236 | 17 | 236 | 17 | 236 | 17 | 236 |
先取第一列的67, 246, 182, 70,再取第二列的67, 246, 182, 70, 85,246,230 ,247,依次类推最终结果是67, 246, 182, 70, 85,246,230 ,247 ……… ……… ,38,6,50,17,7,236。
对于纠错码也是一样的操作:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| block 1-1 | 213 | 199 | 11 | 45 | 115 | 247 | 241 | 223 | 229 | 248 | 154 | 117 | 154 | 111 | 86 | 161 | 111 | 39 |
| block 1-2 | 87 | 204 | 96 | 60 | 202 | 182 | 124 | 157 | 200 | 134 | 27 | 129 | 209 | 17 | 163 | 163 | 120 | 133 |
| block 2-1 | 148 | 116 | 177 | 212 | 76 | 133 | 75 | 242 | 238 | 76 | 195 | 230 | 189 | 10 | 108 | 240 | 192 | 141 |
| block 2-2 | 235 | 159 | 5 | 173 | 24 | 147 | 59 | 33 | 106 | 40 | 255 | 172 | 82 | 2 | 131 | 32 | 178 | 236 |
交替拿到的结果是:213,87,148,235,199,204,116,159,…… …… 39,133,141,236
把这两组交替结果放到一起,源数据的在前面:
67, 246, 182, 70, 85,246,230 ,247 ……… ……… ,38,6,50,17,7,236, 213,87,148,235,199,204,116,159,…… …… 39,133,141,236
最终的数据
对于某些版本的二维码,上面的结果不足填充满整个数据区+纠错码区,需要再在末尾补上一些 0,具体补多少个可以参照这个表:
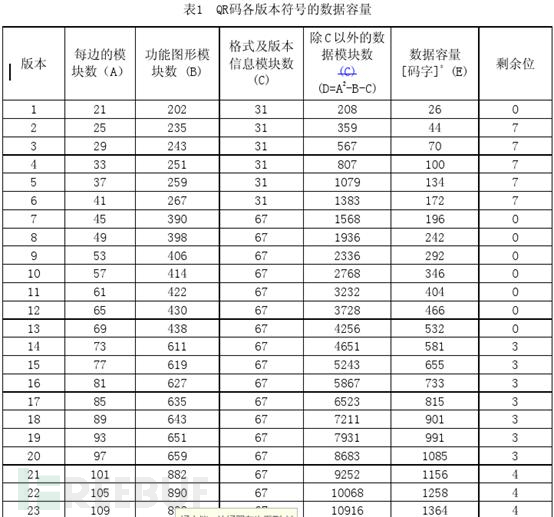
版本 5 的二维码图案里,数据区+纠错码区一共有1079位,而我们上面的结果只有 134 个字节也就是1072位,所以需要再补上 7 个 0。
以上就是最终的数据了!
绘制二维码
终于到了这一步,好累 😫,所幸这一步比较轻松。
3 个位置探测方块
先把三个大“回”字画整起来!分别放在左上、右上和左下角,回字的大小是固定的,可以看最开始的介绍。
然后他们外围的一圈白色位置探测分隔符也可以直接画上。

N 个校正方块
校正方块是比较小的回字,它的大小也是固定的,只不过不同的版本都不同数量的校正方块:
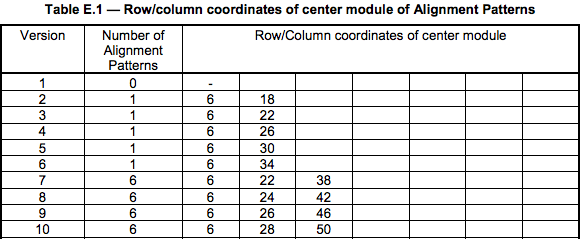
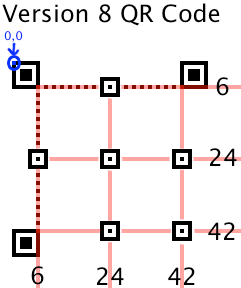
举例version 8的(6,24,42)是如何画校正图形的:
2 个定位条(Timing Patterns)
在确定位置探测方块后,这两根条就很好画了。
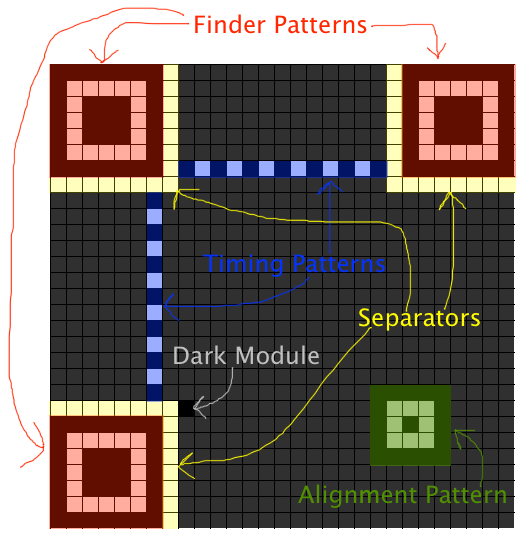
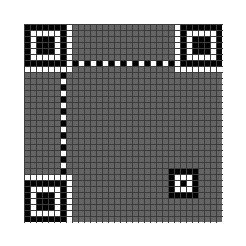
头尾固定是黑色,中间黑白相间。
格式信息
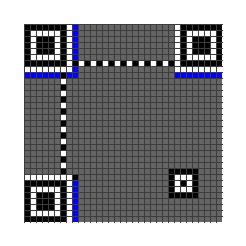
格式信息画在上面的蓝色部分,是固定 15 位的二进制串,具体组成部分为:
2 位表示纠错级别,一共有 4 种纠错级别。
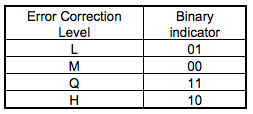
3 位表示使用何种掩码图案,一共有 8 种掩码图案,具体要使用哪一个掩码在后面会具体介绍

10 位纠错信息,使用 BCH 编码 计算得出
- 上面的 15 位再和固定的
101010000010010做异或操作,这样就保证不会因为选用了00的纠错级别和000的 掩码图案,从而造成全部为白色,这会增加扫描器的图像识别的困难。
举个例子:

15 位的具体分布如下:
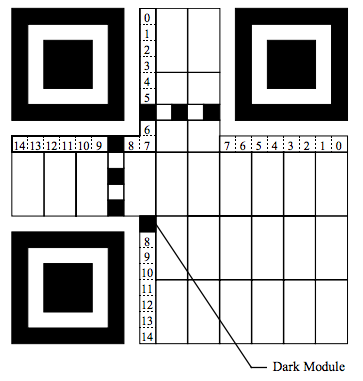
Dark Module表示一个固定是黑色的块。
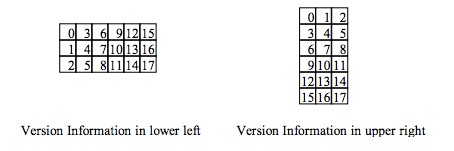
版本信息
版本号大于等于 7 时,需要绘制这个部分,下面的蓝色部分。

版本信息一共有18位,其中包括
- 6 位表示版本号,一共有 40 个版本号
- 12 位表示纠错信息,也是使用 BCH 编码计算得出
例如:

这 18 位的具体分布如下:
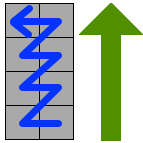
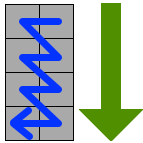
数据区+纠错码区
终于到了这一步了,我太难了 😿😢😂
从二维码的右下角开始,沿着红线填充我们数据编码的每一个bit,1表示黑色,0表示白色,遇到非数据区绕开或跳过。

掩码图
以上还没有结束 😭,因为可能上面画出来后,黑白分布不均匀导致存在大片的白色或黑色,造成扫描识别的困难。
为了解决这个问题,二维码提供了8种Mask掩码图案:

我们需要拿着上面生成的图案和掩码图案做一次异或操作,这样黑白分布就会均匀很多!
那具体选择哪一个掩码图案呢?也是有一个灰常复杂的计算方案,大体步骤是分别将原始图案和每一个掩码图案做异或,然后按照一套规则来计算均匀程度,最终选择最均匀的那个。
💐💐💐,终于到这里二维码的绘制就结束了!!
最后提供一个表示HElLO WORLD的二维码:

想要了解如何使用代码来生成二维码的同学,可以参考qrcode.js, 也有很多其他开源的库,感兴趣可以自己去搜一下。
这个二维码生成工具可以直接输入一个字符串并输出一个二维码。
解码过程
实际上编码过程反过来就是解码过程:
- 拿到版本信息、格式信息,反向异或一次就可以得到原始信息
- 原始信息里包含掩码图案信息,将二维码和源码图案再做一次异或,就能得到原始二维码图案
- 去掉位置探测区域、校正区域等等所有功能图形,留下的部分就是
源数据编码+纠错码+若干用于补齐的0 - 根据版本+纠错级别,可以知道源数据编码和纠错码分别有多长,以及交替顺序是怎样的
- 源数据编码的前 4 位表示编码模式,紧接着的 9 位表示原始字符串长度,根据版本+纠错级别也能知道随后的哪些表示源字符串的编码部分
- 根据编码模式解码得到源字符串
以上并没有提到到当二维码有污损时的解码过程,因为这时就涉及到纠错码的戏份了,还是留给代码去做这个累活吧 😆
这篇文章的最后给了一个手动解码的示范,感兴趣的可以自己观摩一下。
网上也有很多免费提供二维码解码服务的页面,例如这个。 去看看自己的个人微信二维码解密后是什么呢?🤔