在国际化业务中总有很多地方需要做本地化,比如地域列表在不同国家地区的展现,在英语国家更习惯A-Z的排序,国内更习惯拼音排序。再精细一些的业务场景中,会遵循专业翻译人员的意见给出更本地化的排序,比如法语、意大利中会有很多带音调的字母如Â、ñ、Ï。
本文会尝试手动实现这样的排序标准,看看其中有哪些坑,并给出最终的方案。
排序标准
排序最核心的就是确定不同语言下的排序标准,这个是交给专业翻译来确定的,同时可能会结合具体业务做细节上的调整。下面给一些在我所在业务部分语种的排序标准。
英语:A a B b C c D d E e F f G g H h I i J j K k L l M m N n O o P p Q q R r S s T t U u V v W w X x Y y Z z
日语:あ、い、う、え、お、か、き、く、け、こ、さ、し、す、せ、そ、た、ち、つ、て、と、な、に、ぬ、ね、の、は、ひ、ふ、へ、ほ、ま、み、む、め、も、や、ゆ、よ、ら、り、る、れ、ろ、わ、を、ん
葡萄牙语:
A a Á á B b C c D d E e É é F f G g H h I i Í í J j K k L l M m N n O o Ó ó P p Q q R r S s T t U u Ú ú V v W w X x Y y Z z
俄语:А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
排序函数
内置 sort
js内置支持sort方法,不过它内部的排序标准比较简单,只是将两个参数相减,如果前者比后者小就返回负数。直接将sort应用于英文的排序发现就产生了不一致:
1 | function sort1(arr, locale) { |

当然仅仅修复英文的排序还是比较简单的,只需针对大小写做一些特殊判断。
修复大小写优先级
1 | function sort2(arr) { |

实际上这段排序可以满足我们业务的英语、德语、日语、韩语、马拉西亚、泰语、印度尼西亚、阿拉伯语的排序标准。
但是所有含有音调符的语言,排序全部会失败, 因为那些字母的码点比A-Za-z都要大:
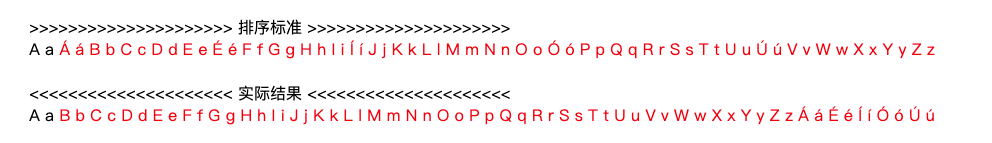
修复音调字符
音调符通常不改变原字符的意义,只是改变它的读音,类似于拼音里的Ā Á Ǎ À,一些变音符的示范。
这些变音符很多都是由基础字符+专门的音调符组合而成的,而且组合而成的字符也是一个专门的Unicode字符, 他们在js的长度也是 1,没有办法直接拆开。
1 | "À".length; // 1 |
幸而es6中针对Unicode字符出了一系列专门的函数,其中就有一个专门用于合成、分解这种变音符的函数normalize
可以给其传入特定的字符串NFD表示“标准等价分解”,还有另一个差不多的NFKD,二者差别不大。比如À的分解结果如下:
1 | const normalized = "À".normalize("NFD"); |
那么利用normalize我们就可以处理变音符号了,修改后的sort方法:
1 | function sort3(arr, locale) { |
在sort2方法的基础上,可以解决葡萄牙、俄国、西班牙语、菲律宾这些语种的排序。
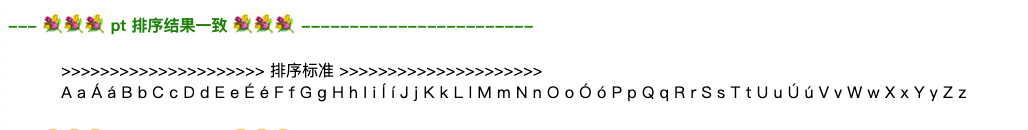
\p{Mark}是es6新增的正则表达式特性: Unicode属性类。
注意:simpleAccentCompare在比较音调符时只单纯比较了码点大小,如果业务上有要求更个性化的排序标准,可以建立一个音调符的优先级映射表。
但在法语的标准中,遇到了一些比音调符更奇怪的字符。。。

经过搜索,他们是捆绑字符Ligature characters>).
修复捆绑字符
捆绑字符将两个或多个字母连在一块,看起来就像是书写时将他们连在一起了。捆绑字符的形式多种多样,而且经过测试normalize也无法处理这种字符。。。
不过业务中通常不会出现这么多捆绑字符,比如翻译人员给的完整排序标准中只有 4 个,翻译文案绝大多数情况下只会使用基本的A-Za-z。作为变通我们可以建立一个映射表将捆绑字符分解,与这篇文章的思路是相同的。 比如
1 | var LIGATURE_MAP = { |
所以我们的sort可以改一改:
1 | function compareChar(char1, char2) { |
这样就修复了捆绑字符的问题:

正当以为坑都踩完了,Unicode告诉我too young too simple, sometimes naive,给我一记重拳。。。还有更大的坑等着我

stroke letter
这种字符中间带一个横杠的,也不知道该怎么称呼,就叫stroke letter吧,在Unicode中还挺多的,给一些例子
stroke letter无法用normalize分解,数量众多也不大好建立映射表,看起来是没有办法的。
无意中看到lodash.deblurr方法,函数注释中说可以处理所有在 Latin-1 Supplement#Character_table>) and Latin Extended-A letters这里两个script的字符,去掉所有combining diacritical marks, 其中就包含很多stroke letter. 它是怎么做的呢?
查看源码可以得知核心的一句是:
1 | function deburr(string) { |
string.replace(reLatin, deburrLetter)是讲所有变音符、stroke letter暴力替换为素颜形式,比如Ł --> L。它在内部维护了一个很大的映射表,基于它来做暴力替换,所以它也只处理了两个script的字符。实在是力不从心。。。
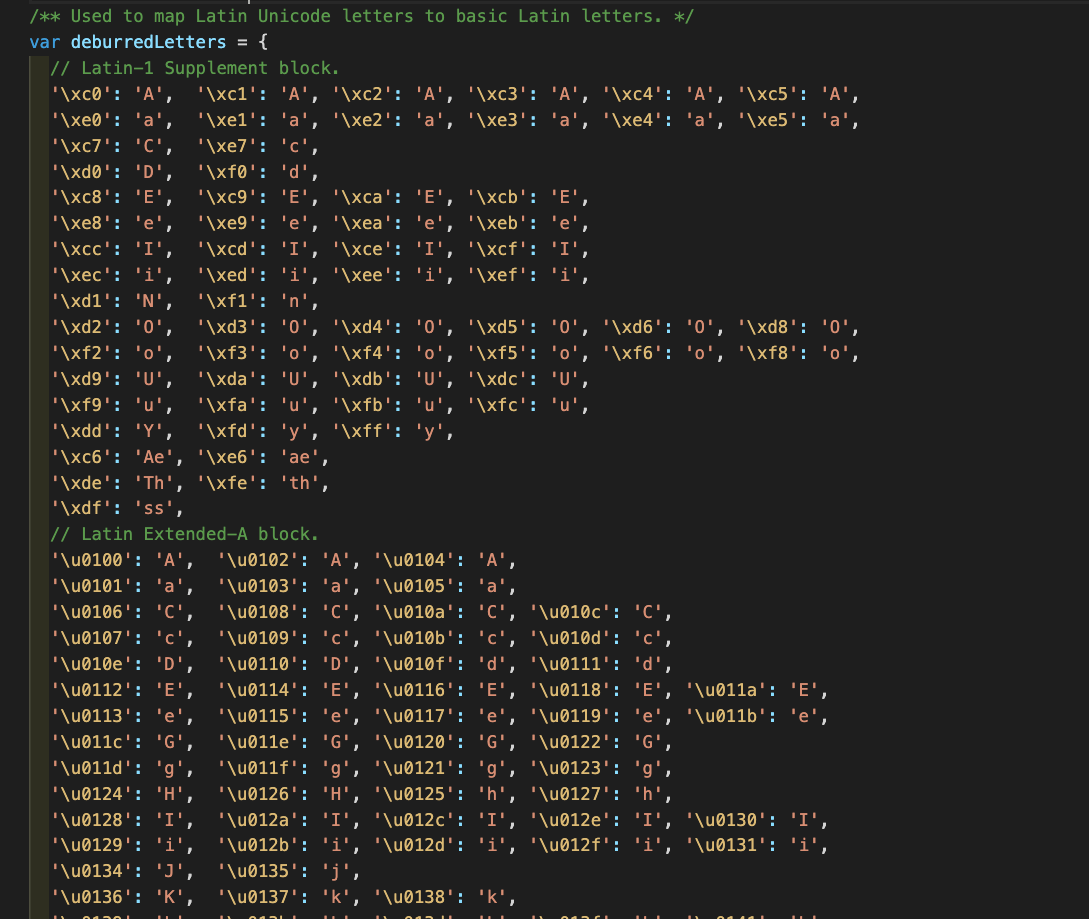
到这里要反思是不是思路不对?目前都是从字符本身着手的,所以需要处理各种各样奇怪的Unicode字符,边界情况非常的多。
localeCompare
换个思路,在业务场景中更多的是先定下来整个页面的语种,然后再基于这个语种来对文案进行排序。也就是说如果页面是日文的,即使文案本身是韩文,也将韩文按照日文的排序标准来排序。 有没有一些能在给定语种的情况下排序的开源库或者函数呢?
在stackoverflow上搜索果然有相关问题,比如这个。其中提到了localeCompare和Intl.Collator,看了下MDN二者其实差不多,传的参数也是一样的。以下就只讨论localeCompare。
函数声明是:
1 | referenceStr.localeCompare(compareString[, locales[, options]]) |
locales参数表明按照什么语种来排序,可以传递数组options提供细节控制,比如sensitivity是否忽略大小写,是否忽略音调符等等caseFirst大写优先还是小写优先numeric数字是否参与比较
稍微棘手的是locales改怎么传,文档中给了一些参考链接以及language-subtag-registry,不过这两还是不大清晰易懂,经过努力又找到另一个文档language code。
我们试试它的效果如何:
1 | function sort5(arr, locale) { |
令人感到惊喜的是stroke letter、捆绑字符、音调符都很好的处理了,只有一小部分的细节与翻译人员定的标准不一致,基本都是多个音调符的顺序不一致。可能是locale设置的不对,也可能是标准本身定的就不是很准确。不一致的部分可以和 PM 沟通看看是否可以接收,因为业务中很有可能是不会出现那些音调符的。
真香!
后续 TODO: 研究 V8 中的localeCompare源码。
总结
本文探索了手写一个多语言排序函数具体会遇到哪些坑,并在最后使用localeCompare满足了业务需求。本文所有涉及代码和排序在这里,右键查看源码即可。