RT,本文主要是为了介绍一种tree组件的实现方式,包含市面上tree组件的常见功能。后面会再专门研究element-ui中的tree内部实现。
数据结构
这是组件最核心的部分,直接关系到各种特性实现的复杂度。
Tree本身
这是用于渲染Tree自身的,通常需要上层业务中传入树形节点数据,例如:
1 | const source = [{ |
1 | // Tree组件 |
树中的每个节点至少会包含id与label两个核心属性,前者是节点唯一标识,后者用于界面展示。那么怎么把它渲染出来呢? 有2种常见的方法:
递归渲染
核心是将树节点单独封装成一个tree-node组件,同时vue允许组件内部直接引用自身。
tree-node组件:
1 | <template> |
这样tree组件自身只要负责把第一层节点渲染即可:
1 | <template> |
打平后直接vfor迭代渲染
如果节点不多,也可以将source打平为一维数组,这样tree组件可以直接v-for一把梭:
1 | <template> |
本质上打平操作是对树的先序遍历,内部也是使用递归访问了一遍完整的树,顺便记录了父节点位置。好处是可以很方便的知道节点的父节点所在位置,直接使用索引访问即可。弊端也比较明显相当于遍历了两遍树,第一遍是在打平时,第二遍是在渲染时。另外如果节点支持懒加载,这种方式也不大容易理解,新加载的节点在打平数组中与父节点可能相隔很远。
此文的后面都基于第一种方式递归渲染来描述。
选中项
tree组件通常支持多选操作:

并且会进行数值合并的情况
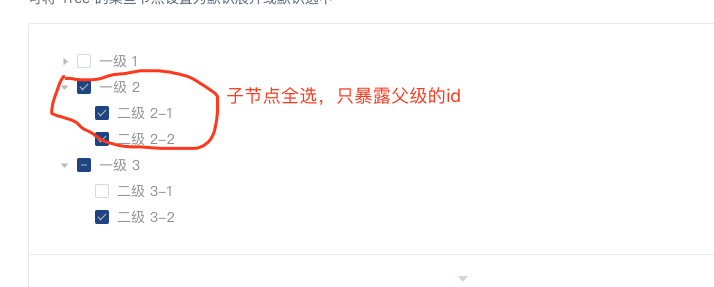
如何支持这种特性呢?这里介绍一种思路:
- 在
tree组件中增加专门的checkedKeys数组,用于记录所有选中的叶子节点。 按照每个节点的叶子节点规模进行倒序得到
sortedTreeNodes数组,例如下面的情况sortedTreeNodes就是[a,b,d,c,e,f,g,h,i,j,k]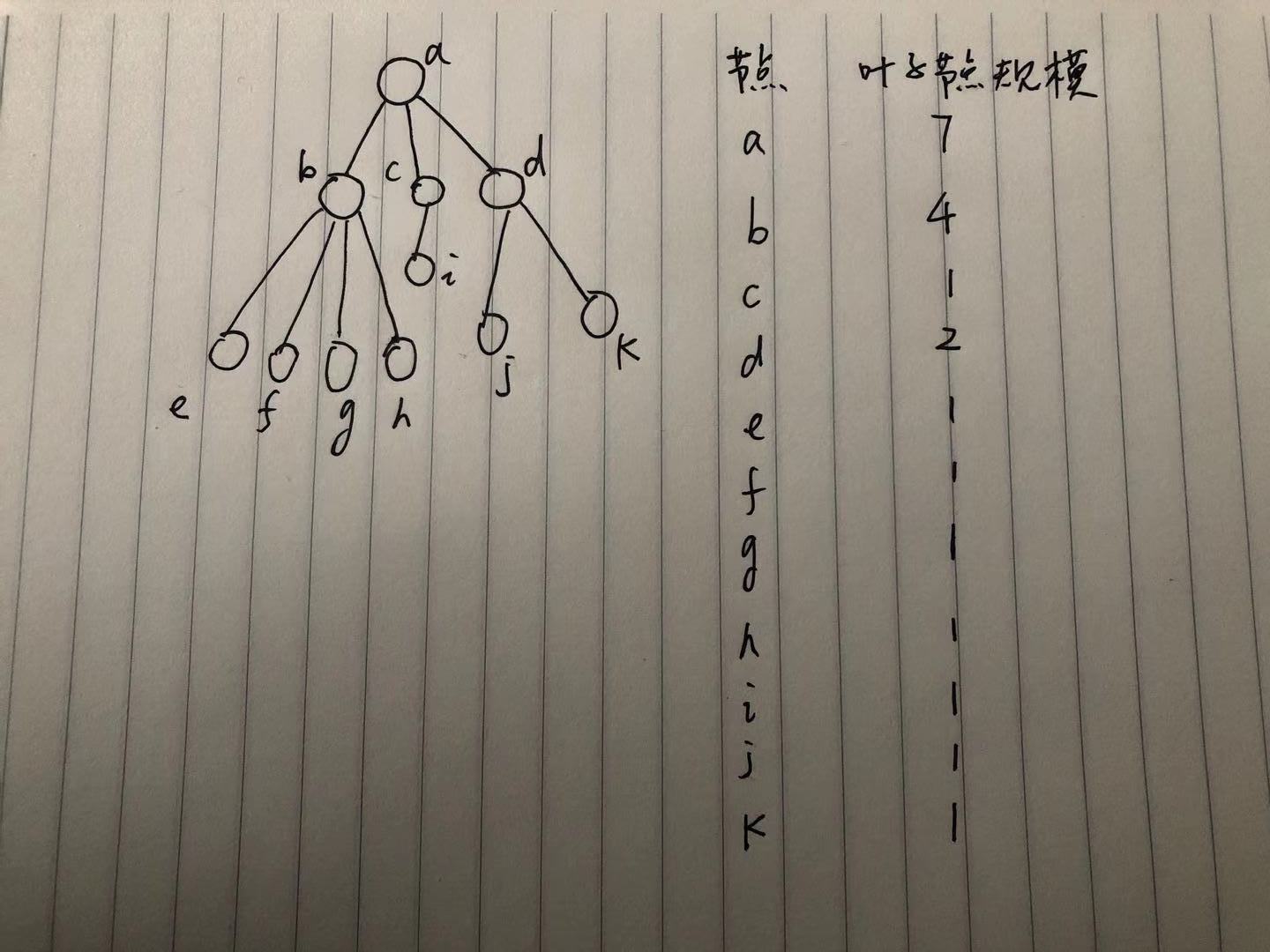
依次判断
sortedTreeNodes中元素,- 如果是叶子节点,直接加入结果集,并从
checkedKeys删除 - 如果是树干节点
- 下属叶子节点全选,则将树干节点加入结果集,下属叶子节点全部从
checkedKeys删除 - 下属叶子节点没有全选,直接跳过此树干节点
- 下属叶子节点全选,则将树干节点加入结果集,下属叶子节点全部从
- 如果是叶子节点,直接加入结果集,并从
为什么要先倒序呢?因为不倒序的话可能得到的结果不对,例如下面这种情况:
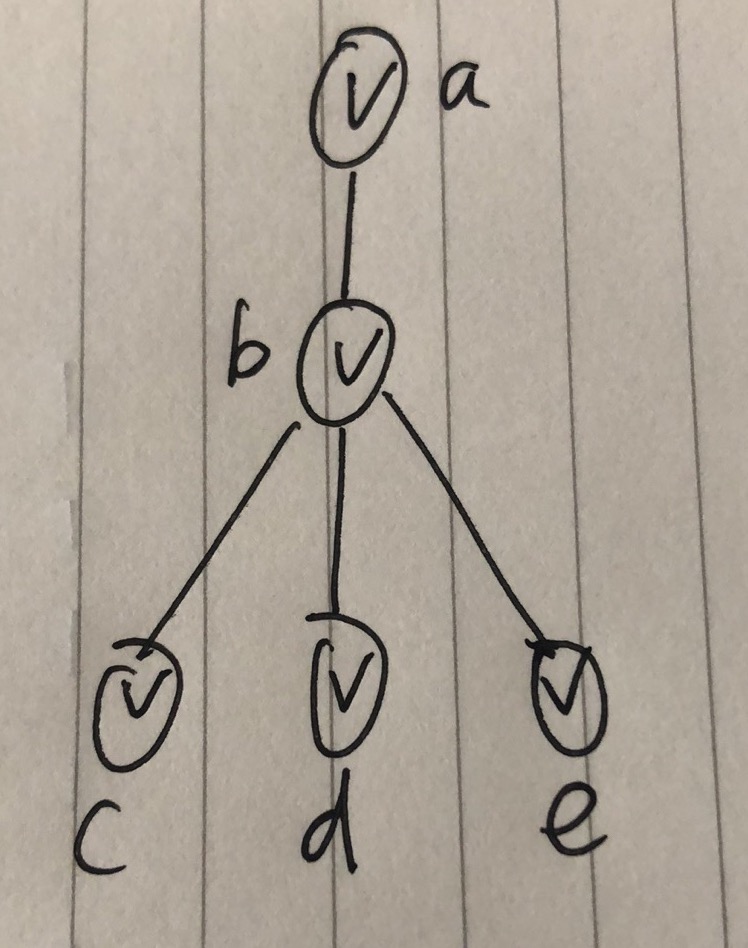
如果先从b节点判断的,那么最终的结果集就是[b],而不是[a].
有了checkedKeys之后,每个tree-node也能方便知道自身是不是选中状态了:
tree-node组件:
1 | computed: { |
throughed value
某些业务中,还会要求拿到每个层级部分选中的节点,throughed value就是一个二维数组,存储每个层级全选/部分选中的节点。例如:
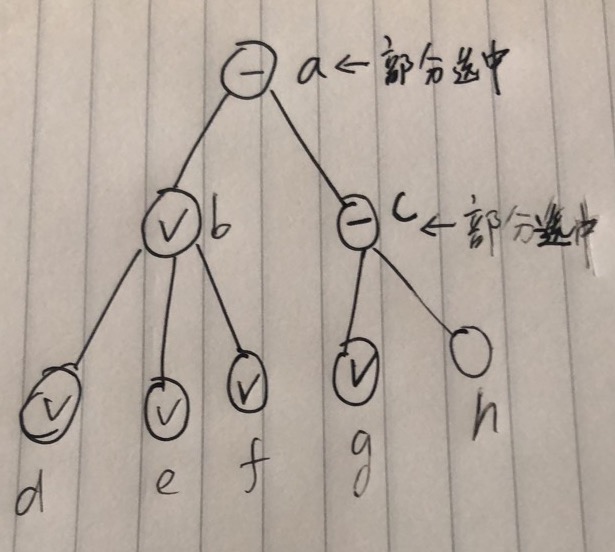
注意节点c下属只有g被选中,所以c是部分选中状态。 那么throughed value就会是:
1 | [ |
如何计算throughed value呢?其实和上面选中项的计算很像,只需改动3.2即可:
如果是树干节点:
- 下属叶子节点全选,则将树干节点加入结果集,下属叶子节点全部从
checkedKeys删除 - 下属叶子节点部分选中,将树干节点加入结果集,但并不操作叶子节点
要注意到,不管是选中项还是throughed value的计算,都依赖对原始数据结构的多次遍历操作,同时还涉及对整个树的排序操作,因此在树规模较大时,不可避免的有性能上问题。一种解决方案是把这些遍历操作转化为节点自身的各种属性,例如判断每个节点自身是否选中,不要看下属叶子的选中情况,而是直接判断自身的checked属性。
展开项
用于控制树干节点是展开还是收起,可以在tree组件中添加一个expandedKeys数组,存放所有已展开树干节点的id。在折叠/展开节点时更新这个数组。 每个tree-node判断自己是否展开,只需看自己的id在不在其中即可。
// tree组件
1 | <script> |
// tree-node组件
1 | <template> |
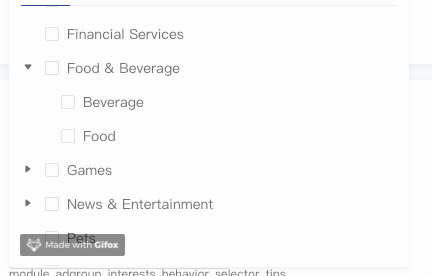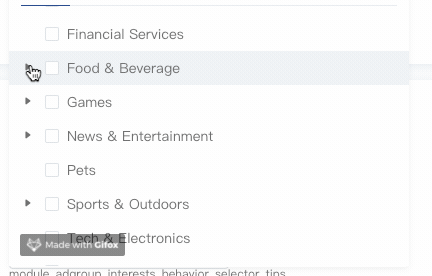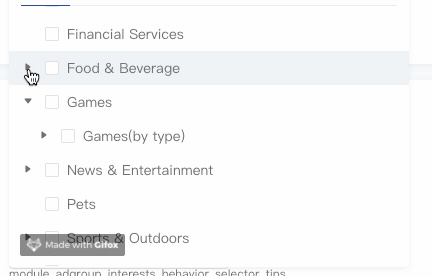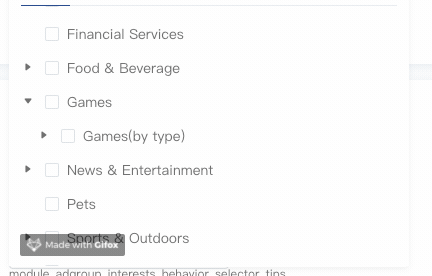
手风琴模式
有了expandedKeys,手风琴模式就很好实现了,关键点就是在展开当前节点时将所有兄弟节点全部从expandedKeys剔除即可:
1 | handleToggleExpand(id) { |
懒加载
对于规模很大的树,一次性将所有节点数据全部拉取并渲染,是有些问题的。一来用户体验差,耗时很长,二来浪费流量,大多数情况下用户只会使用其中很小一部分。 懒加载就是在初始时只加载小部分最主要的数据,剩下的数据看用户点开哪个节点,点击时再去拉取一定的数据。 举例来说:

要实现这个功能有几个关键点:
- 组件需要知道展开哪些节点时是要触发懒加载的
- 组件需要知道如何获取懒加载数据
- 后端接口支持懒加载,至少支持两个参数:
root与depth,前者用于定位子树的位置,后者用于拉取指定量级的数据
第1点可以在节点上加一些特殊标识,如果节点上有hasChildren属性,同时在展开节点前发现当前树中没有任何它的子节点,那么就可以触发懒加载了。
1 | isNeedLoadChildren(treeNode) { |
第2点获取懒加载数据,需要由上层业务决定,基础组件可以接收一个loadChildren的prop,函数的参数是展开的节点,返回值是一个Promise,Promise完成时会拿到子树数据。这样tree组件就可以把子树数据融合进去了。
1 | treeNode.loading = true; |
搜索
树节点变多时,通常会提供搜索功能,搜索分两种:前端本地搜索和远程搜索。前者比较简单,后者结合懒加载会有一些坑需要注意。
本地搜索
本地搜索的关键是组件需要知道搜索关键词keyword,同时允许业务方自定义匹配函数filterMethod。组件内部观察keyword的变化,只展示命中的节点。
1 | watch: { |
懒加载下的搜索
这种场景下的最大困难是前端不知道完整的树是什么样子,前端只有一个局部子树。举两个可能的坑,若某个时刻的情况如下:
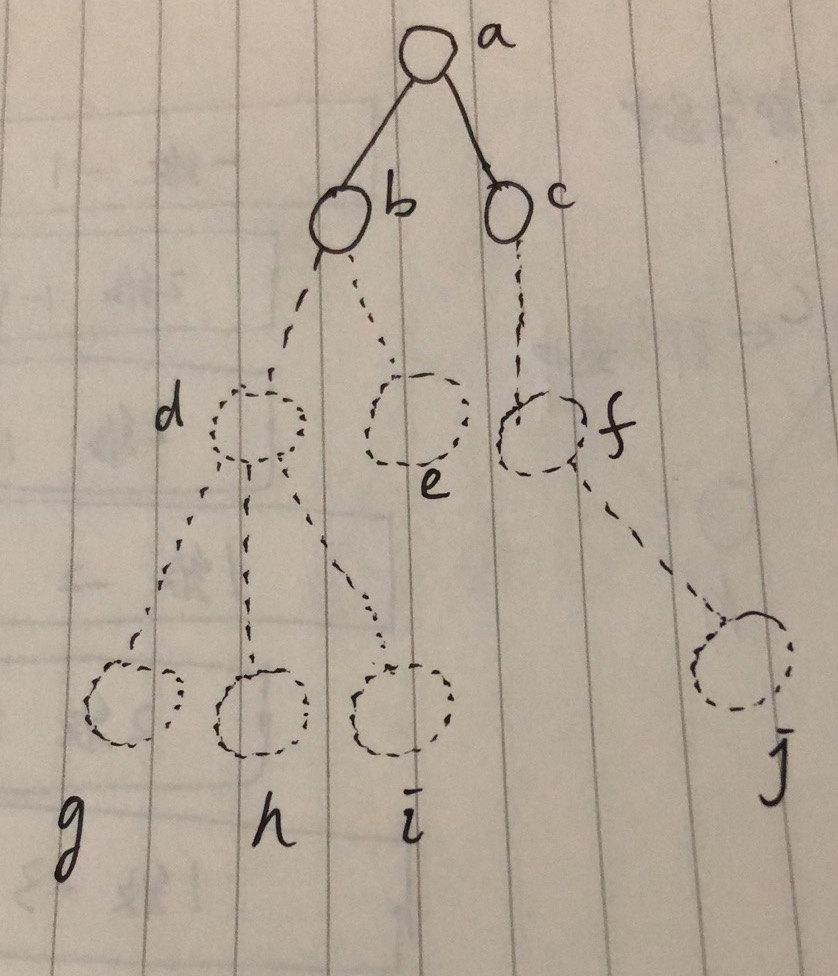
即前端只加载了a、b、c3个节点,剩下的节点并未拉取。
情形1️⃣:搜索某个关键词返后端回的节点是
g、h、i,如果用户将这3个节点全部选中了,返回给上层的选中值不应该是g、h、i,而应该是他们的上层节点d,但前端并不知道d的存在。情形2:如果先勾选了
b节点,然后搜索某个关键词返回的节点是g,此时即使选中g也不应该返回给上层组件,因为g的组件节点b已经被选中了。
解决方案是:后端返回命中节点到根节点的完整通路子树,前端将这个子树直接当做tree组件的新source。例如如果命中了h、i、j,那么返回的子树就是:
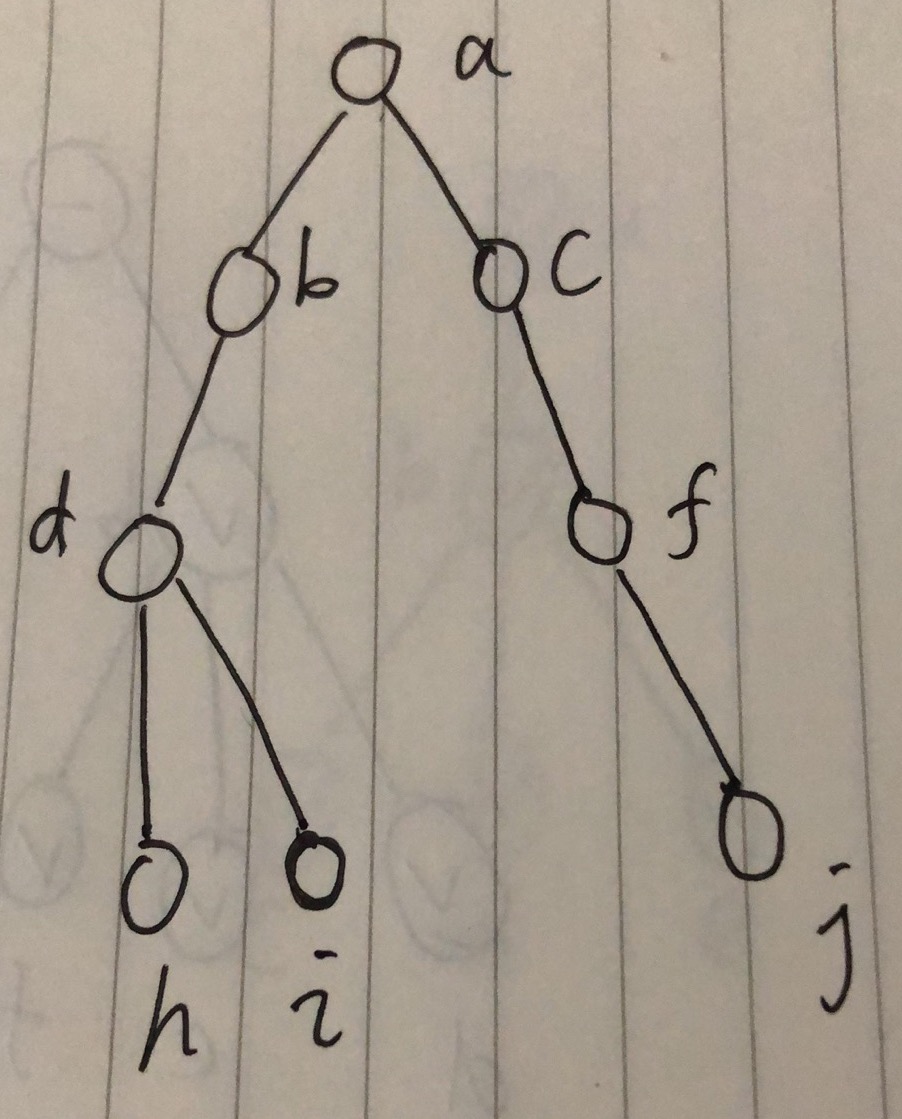
只有这样前端才能知道完整的信息。
吸顶效果
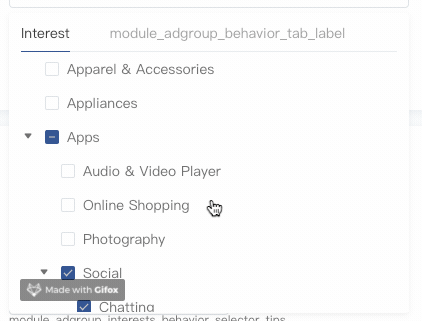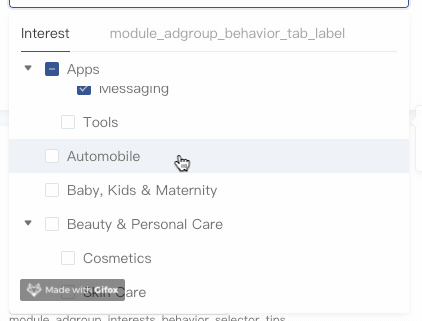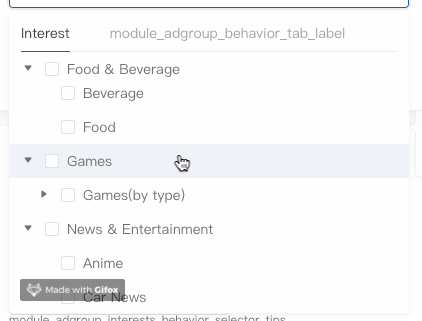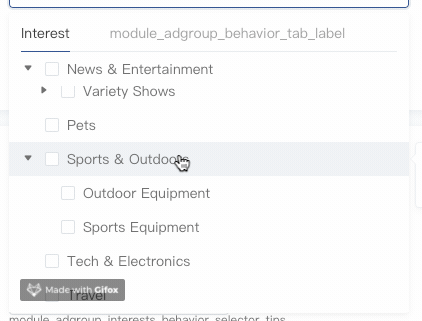
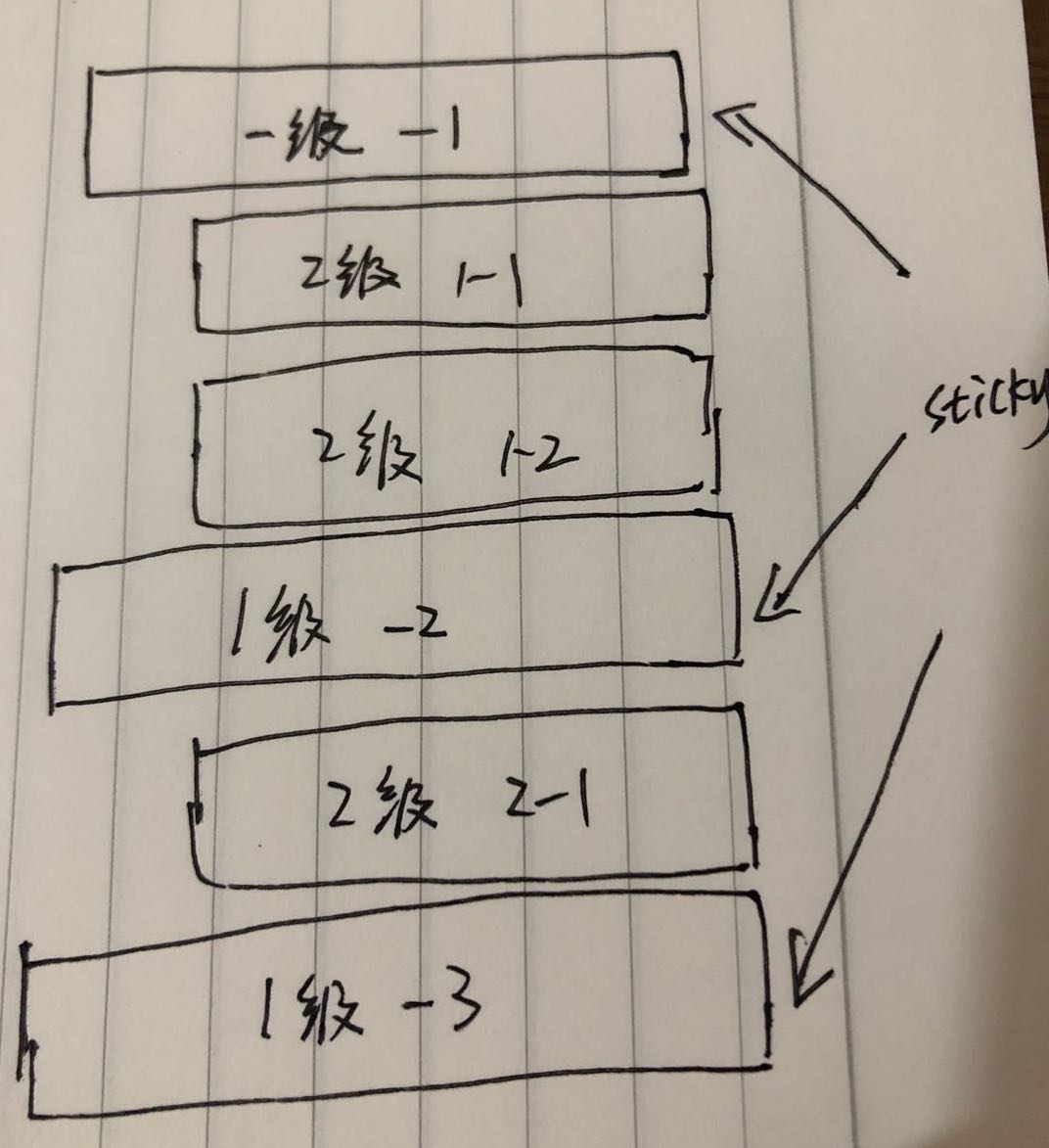
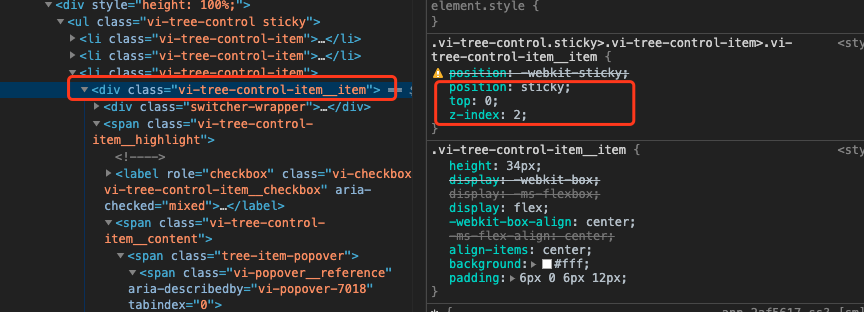
借助position:sticky可以方便实现滚动吸顶,这里只示范第一层级节点的滚动吸顶,其他低层级节点类似,区别在于z-index和top值的设定。
自定义渲染
在很多场景下需要自定义每个节点的渲染,除了默认的label外还会有业务上的特殊定制。例如每个节点hover上去后出现节点的一些明细信息。
自定义渲染的关键在于给业务方暴露slot,同时基础组件内部提供一个最常见的默认实现。
// tree-node组件,提供原始slot
1 | <slot :item="node" name="node"/> |
// tree组件,进行一次转发
1 | <tree-node v-for="node in source" :key="node.id" :node="node"> |
下面是一个常见的自定义渲染示范
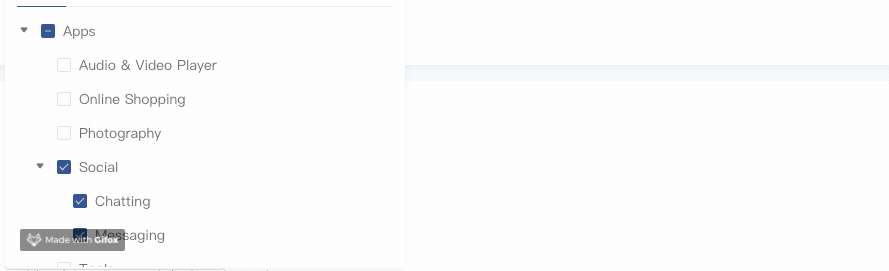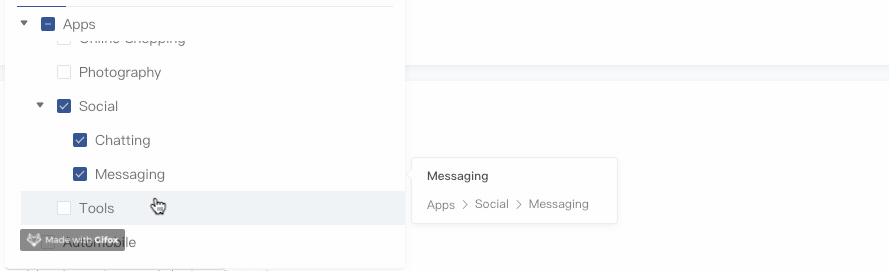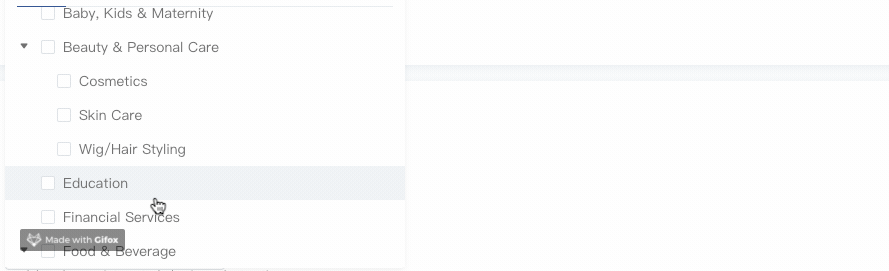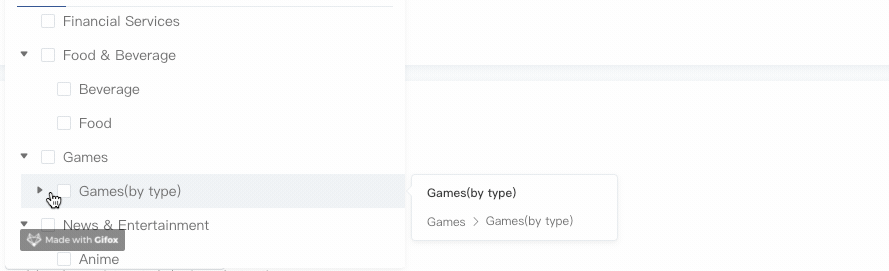
hover & 展示节点面包屑
// 业务组件
1 | <tree :source="source"> |
效果如下:
总结
本文主要介绍了一种tree组件的底层实现细节,并指出了底层数据结构的潜在性能问题和可能的解决方案。