Vue 源码可以分为 3 大块:双向绑定、patch 算法和模板解析。其中又以模板解析最为复杂,它是用来将我们写的template模板编译成render函数,可以猜到如果我们直接写render,那么整个解析过程就可以跳过,而且分析其中的代码可以看出这个解析的过程其实是很独立的。
前面的文章也有提到,模板解析主要分为 3 个步骤:
parse,用于将template解析为ASToptimize,用于优化静态内容的渲染,主要是给静态节点打上一些标记generate,用于根据AST生成render函数
相关的核心代码位于src/compiler/index.js:
1 | const ast = parse(template.trim(), options); |
这篇文章主要说第一步:将template解析为AST,主要思路还是逐步解析template字符串,涉及的代码会比较多。
入口
parse函数定义位于src/compiler/parser/index.js:
1 | /** |
可以很容易看出来最核心的是其中的parseHTML函数,其余都是一些影响解析的配置选项。 另外transforms和preTransforms会在用到时再细说。
parseHTML
这个函数的总体思路是逐步解析html字符串,将html文本分为了几类,分别处理:
- 普通的注释节点
- IE 的条件注释 (
<![开头) - Doctype
- 起始标签
- 结束标签
- 纯文本
script、style、textarea节点
通过正则表达式判断属于何种类型的节点,具体的表达式长什么样碰到了会说。
函数的大体轮廓:
1 | export function parseHTML(html, options) { |
while (html)
这个循环会针对上面提的每种类型做处理,虽然代码比较多,但除了起始标签和结束标签外的逻辑都很清晰易懂,我也添加了非常详细的注释。
1 | while (html) { |
可以看到对于注释、Doctype、条件注释,Vue 通常会直接跳过,在处理纯文本和标签时花费了比较多的代码。我们先把一些零碎的细节理一理,主要是几种正则,以及如何处理comment和纯文本chars的。
正则表达式
comment 注释
1 | const comment = /^<!\--/; // 匹配 <!-- |
conditionalComment 条件注释
1 | const conditionalComment = /^<!\[/; // 匹配<![ |
doctype
1 | const doctype = /^<!DOCTYPE [^>]+>/i; // 匹配<!DOCTYPE xxx> |
endTag 结束标签
1 | const ncname = '[a-zA-Z_][\\w\\-\\.]*'; // 以a-zA-Z_开头,后面连接多个a-zA-Z-. |
startTagOpen 起始标签
1 | const startTagOpen = new RegExp(`^<${qnameCapture}`); // 起始标签 |
测试:
1 | '<svg:path />'.match(startTagOpen); // ["<svg:path", "svg:path", index: 0, input: "<svg:path />"] |
attribute 标签属性
1 | const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/; // 匹配标签属性,如href="www.baidu.com" 或 href='www.baidu.com' |
测试:
1 | "href='https://www.baidu.com'".match(attribute); // ["href='https://www.baidu.com'", "href", "=", undefined, "https://www.baidu.com", undefined, index: 0, input: "href='https://www.baidu.com'"] |
options.comment
这个是用于处理遇到的 html comment:
1 | comment (text: string) { |
currentParent是当前正在处理标签元素的父元素,后面还说详细说到。
options.chars
处理遇到的纯文本。
1 | chars (text: string) { |
inVPre我们很少用到,可以当做false处理。这里遇到一个parseText函数,如注释所说是用于处理文本中的插值表达式的。
parseText
1 | /** |
tagRE表示如何匹配插值表达式,默认配置/\{\{((?:.|\n)+?)\}\}/g,表示匹配\{\{ xxx \}\}。另外要注意的是插值表达式可以和过滤器一起使用,所以这里也做了处理。
parseFilters
parseFilters将入参看成是 expression+filters的结构,最终返回一个拼接的字符串。
1 | const validDivisionCharRE = /[\w).+\-_$\]]/; |
这个函数会将参数字符串按字符挨个处理,因为插值表达式的形式很多样,代码注释里有给出一些例子可以看看。
起始标签
在说完while(html)循环中的一些边界处理后,剩下的就是两个重头戏开始标签和结束标签了。
parseHTML对这俩的处理有点类似括号匹配的做法,每当遇到起始标签时就把它放到一个堆栈里。在遇到一个结束标签时,通常此时的栈顶就是对应的起始标签。整个 html 的处理过程就随着入栈出栈的操作不断进行。等到处理完 html 之后,如果没错这个堆栈正好也会变成空的。
在while(html)循环中处理起始标签的代码很少,就是调用了 2 个函数:
1 | // Start tag起始标签,如<p> |
parseStartTag
解析起始标签,同时处理标签上的属性。
1 | function parseStartTag() { |
比如此时的html为
1 | <div id="app">xxxxxx</div> |
则返回结果为:
1 | { |
handleStartTag
主要是继续处理parseStartTag返回值的attrs属性,并最终调用parse中传入的start选项。
1 | // match的格式就是上面的parseStartTag返回值 |
options.start
这里的逻辑很多,核心逻辑是解析节点上的各种静态、动态绑定。在这里我们会生成 AST 节点。
1 | // 参数示范 |
AST 节点
createASTElement用来创建一个 AST 节点,看看长什么样:
1 | function createASTElement(tag: string, attrs: Array<Attr>, parent: ASTElement | void): ASTElement { |
很简单的几个属性,意义也很容易猜出来。不过parse的过程中可能一些 AST 节点上会添加各种其他属性。
preTransforms
目前只有针对v-model的处理,这块逻辑有点多,不过代码比较简单,看注释即可。
1 | function preTransformNode(el: ASTElement, options: CompilerOptions) { |
processPre
处理v-pre指令, 如<span v-pre>\{\{ this will not be compiled \}\}</span>, 若节点上有v-pre,则el.pre=true.
1 | function processPre(el) { |
processRawAttrs
处理 AST 节点上的attrsList属性,将他们复制到attrs上去。
1 | function processRawAttrs(el) { |
processFor
处理v-for,例如处理的起始标签为<div v-for="(value,key,index) in items">,那么此时传入的el为
1 | { |
1 | function processFor(el: ASTElement) { |
parseFor来拆解v-for表达式:
1 | export function parseFor(exp: string): ?ForParseResult { |
若v-for属性值为‘(value,key,index) in items’,parseFor处理后在ast上添加的属性有:
1 | { |
processIf
对于v-if, v-else-if和 v-else,实际上在不同阶段都有对应处理,主要是因为它可以有多个分支,最终渲染哪个分支需要根据绑定的值来决定,所以比较复杂。
1. processIf
处理节点上的 v-if 属性。
1 | function processIf(el) { |
若 html 为
1 | <div v-if="condition">this is v-if</div> |
则processIf会调用 3 次,每次的差别在于attrsMap里的属性值
1 | { |
2. 在处理到v-else-if and v-else节点时, 需要将其和 v-if 节点结合起来:
1 | if (currentParent && !element.forbidden) { |
processIfConditions用于将v-else-if或v-else上绑定的表达式都统一放到v-if节点上的ifConditions数组数组中。
1 | function processIfConditions(el, parent) { |
最终会在v-if标签节点对应AST的ifConditions数组中存放了所有的可能分支,这个数组的格式为
1 | { |
在render时会找到 exp 成立的那个元素,渲染对应的block。
processOnce
处理v-once,这个指令只渲染元素和组件一次。随后的重新渲染,元素/组件及其所有的子节点将被视为静态内容并跳过。这可以用于优化更新性能。
1 | function processOnce(el) { |
processElement
处理ref、slot、is、指令以及其他所有普通属性.
1 | export function processElement(element: ASTElement, options: CompilerOptions) { |
内部调用了多个其他函数,挨个来说是做什么的。
processKey
获取静态或动态绑定的key属性.
1 | function processKey(el) { |
processRef
获取动态绑定的ref属性,并检查是否位于v-for当中。
1 | function processRef(el) { |
processSlot
处理slot插槽, 插槽有 3 种形式:
- 定义插槽:
<slot name='xxx'>或<slot> - 作用域插槽:
<template slot-scope="slotScope"></template>. 在定义插槽时绑定在slot元素上的值会传递给slotScope - 使用插槽:
<p slot="xxx"></p>
1. 处理插槽和作用域插槽,获取 slotName、slotScope、slotTarget
1 | function processSlot(el) { |
2. 生成 scopedSlots 映射
1 | if (currentParent && !element.forbidden) { |
processComponent
处理is属性,将对应值设置到component属性上.
1 | function processComponent(el) { |
transforms
v-model的preTransform是在processElement之前执行,而class和style的处理是在processElement之内处理的,而且处理方法很类似。
transforms目前只在class和style的module中有定义,见src/platforms/web/compiler/modules文件夹。
其中
class的transforms作用:- 获取静态绑定的
class属性,放到el.staticClass - 获取动态绑定的
class属性,放到el.classBinding
- 获取静态绑定的
style的transforms作用:- 获取静态绑定的
style属性,放到el.staticStyle - 获取动态绑定的
style属性,放到el.styleBinding
- 获取静态绑定的
这里只展示class的源码:
1 | function transformNode(el: ASTElement, options: CompilerOptions) { |
processAttrs
处理element上的所有属性,根据属性名分为指令和普通属性,v-on的处理也会在这里。
对于动态绑定属性的处理会比较复杂,静态绑定很简单。
1 | function processAttrs(el) { |
上面的if (dirRE.test(name))分支就是用来处理动态绑定的属性,是匹配v- 或 @ 或 : 开头的属性名. 相比之下静态属性就是简单的调用addAttr放到el.attrs即可。
动态绑定属性的分支代码:
1 | // mark element as dynamic |
v-bind的修饰符有 3 种,prop、camel和sync,官网上的解释很清楚,可以自己去看下。
其他注释已经很清楚了,需要再看看的是其中调用的一些帮助函数,挨个说下。
parseModifiers
获取绑定的修饰符,注意不仅仅是`@event.m1.m2可以加修饰符,:prop.m1.m2`也是可以加的哦~
1 | function parseModifiers(name: string): Object | void { |
若存在修饰符则返回一个对象,类似{m1: true, m2:true}.
addHandler
添加事件监听,处理el.nativeEvents或el.events对象.
1 | export function addHandler(el: ASTElement, name: string, value: string, modifiers: ?ASTModifiers, important?: boolean, warn?: Function) { |
最终el.nativeEvents或el.events对象,他们的格式为
1 | { |
handler 格式
1 | { |
针对不同的内置修饰符,eventName的格式有所不同,如name.once会变成 ~name.
实验
可以看到整个流程涉及的东西非常多,很容易蒙圈。最好的办法就是写一个小 demo,然后逐步打断点看看每一步的结果。例如:
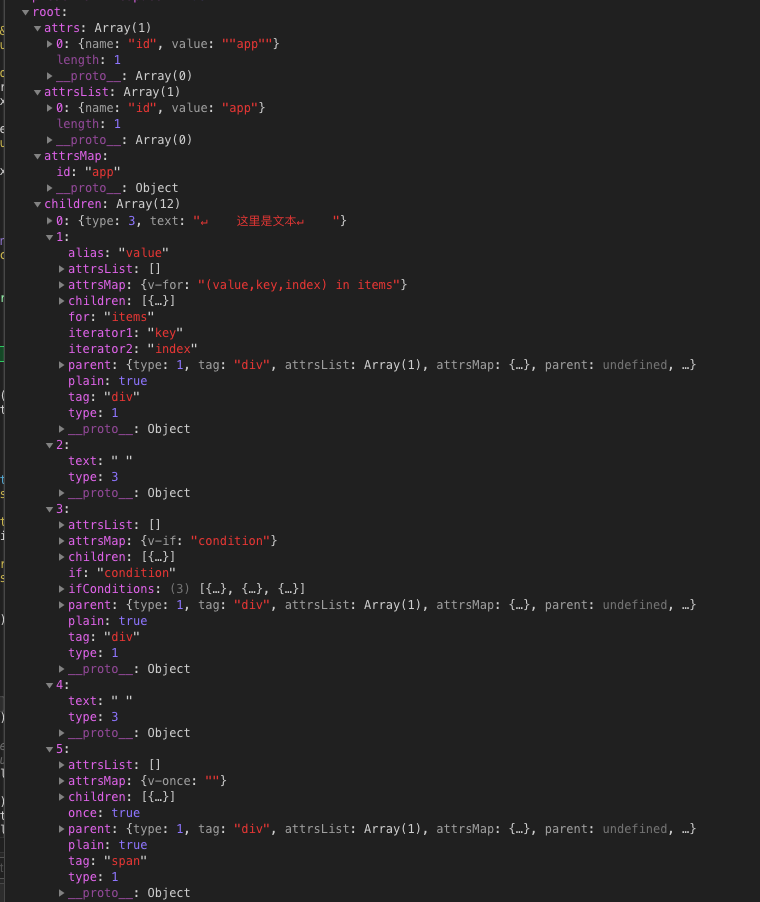
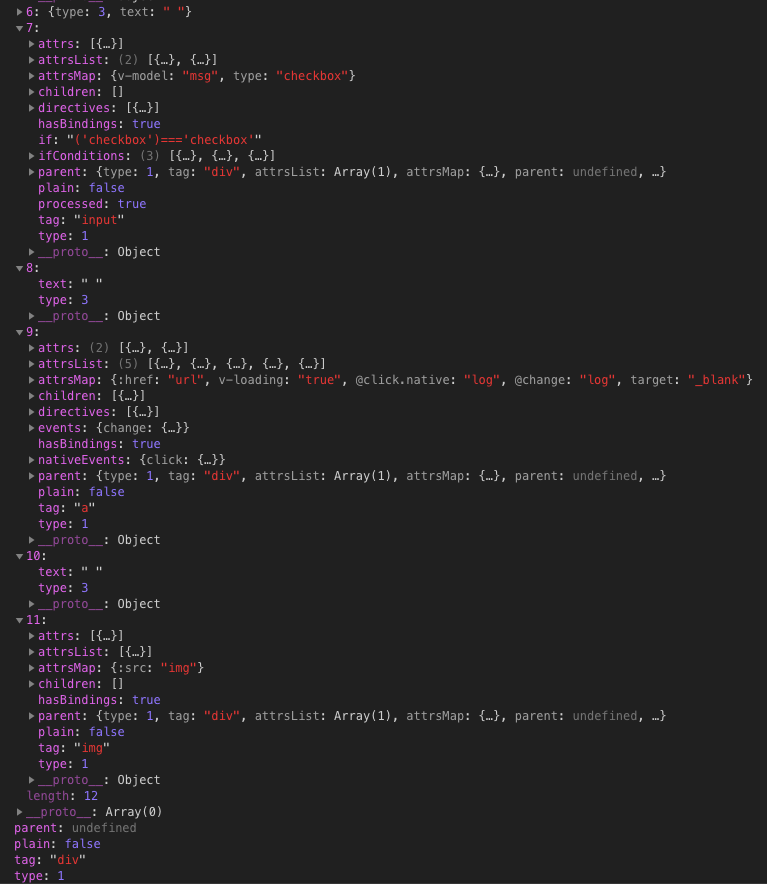
1 | <div id="app"> |
最后生成的 AST 为: